

Introduction
In the era of big data, the importance of clean and high-quality data cannot be overstated. Data cleaning is a crucial step in the data preprocessing pipeline, aimed at identifying and rectifying errors, inconsistencies, and inaccuracies in datasets. Traditionally, data cleaning has been performed using Python and other programming languages. However, with specialized data quality tools, organizations now have alternative solutions at their disposal. In this blog, we’ll explore the “Python vs. Data Quality Tools for Data Cleaning” debate, highlighting the respective strengths and weaknesses of each approach through examples and code snippets.
Data cleaning in Python
Python has become a go-to language for data cleaning and preprocessing tasks due to its simplicity, versatility, and rich ecosystem of libraries. Let’s consider an example where we have a dataset containing customer information, and we need to clean it before further analysis.
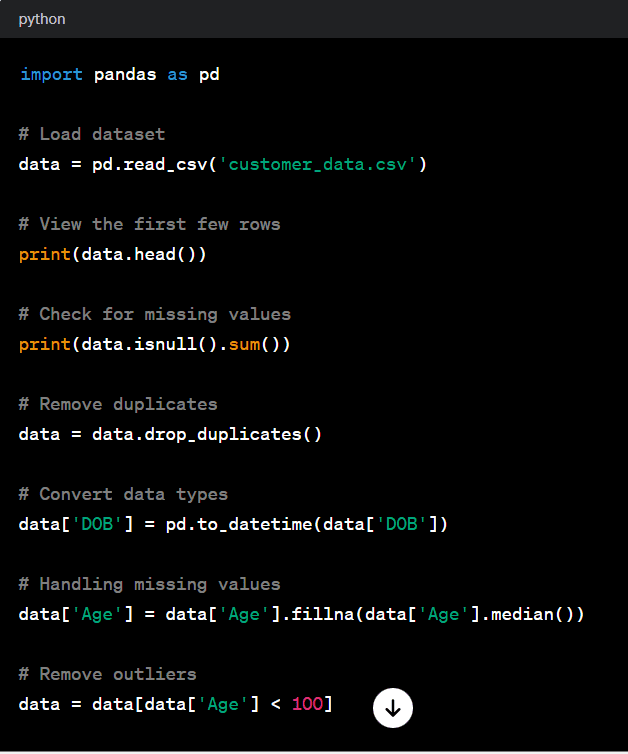
In this example, we utilize the Pandas library to load, clean, and preprocess the dataset. We perform tasks such as handling missing values, removing duplicates, converting data types, and filtering out outliers. Python provides great flexibility in custom cleaning routines tailored to specific dataset characteristics.
Pros and cons of cleaning data in Python
Pros
Flexibility
Python offers immense flexibility in data-cleaning tasks. With libraries like Pandas, NumPy, and scikit-learn, users can implement custom cleaning routines tailored to the specific characteristics of their datasets. This flexibility allows for intricate data manipulation and transformation, accommodating diverse data formats and structures.
Extensive ecosystem
Python boasts a rich ecosystem of libraries for analyzing and manipulating data. Beyond cleaning, users can seamlessly integrate data cleaning tasks with other data preprocessing, analysis, and visualization tasks using popular libraries like Matplotlib, Seaborn, and SciPy. This integration streamlines the entire data pipeline, enhancing productivity and efficiency.
Scalability
Python’s scalability makes it suitable for handling large datasets and performing data cleaning tasks at scale. Libraries like Dask and Apache Spark enable parallel and distributed computing, allowing users to process massive datasets efficiently across clusters of machines. This scalability is advantageous for organizations with big data and complex cleaning requirements.
Reproducibility
Python facilitates reproducible data cleansing workflows through scripting and version control. By encapsulating data cleaning tasks in scripts or Jupyter Notebooks, users can easily document their cleaning processes, track changes, and reproduce results. This enhances transparency, collaboration, and accountability in projects.
Community support
Python benefits from a vibrant and active community of data scientists, analysts, and developers. This community-driven ecosystem fosters knowledge sharing, collaboration, and innovation, with many resources, tutorials, and forums available for troubleshooting and learning. Users can effectively leverage community-contributed packages and solutions to common challenges.
Cons
Learning curve
Python has a moderate learning curve, especially for users with limited programming experience. While Python’s syntax is relatively straightforward and intuitive, mastering its libraries and best practices for data cleaning may require time and effort. Beginners may encounter challenges in understanding advanced concepts such as vectorized operations, function chaining, and method cascading in Pandas.
Performance overhead
Python’s interpreted nature may introduce performance overhead, particularly for computationally intensive data cleansing tasks. Certain operations in Pandas, such as looping over DataFrame rows or applying functions element-wise, may exhibit suboptimal performance compared to lower-level languages like C or C++. Users may need to optimize their code using vectorization, caching, or parallelization techniques to mitigate performance bottlenecks.
Memory management
Python’s memory management model may pose challenges when working with large datasets, leading to memory leaks or inefficient memory utilization. Users must be mindful of memory consumption, especially when loading and manipulating sizable datasets in memory. Techniques like chunking, streaming, or using specialized data structures can help alleviate memory issues but require careful implementation and monitoring.
Lack of built-in data quality tools
While Python offers extensive data manipulation and analysis libraries, it needs built-in tools specifically designed for comprehensive data quality assessment and improvement. Users may need to rely on third-party libraries or develop custom solutions to address data profiling, anomaly detection, and error correction. This can complicate workflows and require additional tool selection and integration effort.
Maintenance and documentation
Python-based data cleaning scripts and workflows require maintenance and documentation to ensure long-term usability and reproducibility. Users need to maintain code hygiene, update dependencies, and refactor code to accommodate changes in data requirements or business logic. Additionally, comprehensive documentation is essential for facilitating knowledge transfer, onboarding new team members, and ensuring the sustainability of data processes over time.
In summary, while Python offers numerous advantages for data cleaning, including flexibility, scalability, and a robust ecosystem, users should be mindful of potential challenges such as the learning curve, performance overhead, and the need for maintenance and documentation. By leveraging Python’s strengths and proactively addressing its limitations, organizations can harness its capabilities for efficient and effective data cleaning.
Data quality tools
Data quality tools offer a more automated and user-friendly approach to data cleaning, often with built-in functionalities for profiling, cleansing, and monitoring data quality. These tools typically come with user interfaces that allow users to define cleaning rules and workflows without writing code. Let’s illustrate this with an example using a popular data quality tool.
1. Import the dataset into the tool.
2. Explore the dataset using visual profiling tools to identify missing values, outliers, and inconsistencies.
3. Define cleaning rules through the GUI, such as removing duplicates, imputing missing values, and standardizing formats.
4. Preview the transformed data to ensure desired outcomes.
5. Execute the cleaning workflow to generate cleaned data.
6. Export the cleaned dataset for further analysis or integration with other systems.
Data quality tools like Astera offer a more intuitive and streamlined approach to data cleaning, particularly suitable for users who may need more programming skills. They efficiently handle large and complex datasets and provide robust features for data quality assessment and improvement.
Pros and cons of using data quality tools
Pros
User-friendly interface
Data quality tools typically feature intuitive user interfaces that allow data cleaning tasks without writing code. This approach simplifies data cleaning, enabling business users and stewards to participate in data quality initiatives without requiring advanced programming skills.
Automation
Data quality tools offer automation capabilities for profiling, cleansing, and monitoring data quality. These tools leverage algorithms and predefined rules to automatically identify and rectify common data errors, inconsistencies, and anomalies. By automating repetitive cleaning tasks, data quality tools reduce manual effort, minimize human errors, and ensure consistency across datasets.
Built-in functionality
Data quality tools have many built-in functionalities for data profiling, cleansing, enrichment, and validation. These functionalities include deduplication, standardization, imputation, validation rules, and reference data matching.
Scalability and performance
Data quality tools are designed to efficiently handle large and complex datasets. They are equipped with optimized algorithms and processing engines capable of scaling to meet the demands of enterprise-scale data cleaning initiatives. These tools leverage parallel processing, distributed computing, and in-memory processing techniques to achieve high performance and throughput.
Governance and compliance
Data quality tools offer data governance, compliance, and auditability features. They provide capabilities for tracking data lineage, documenting cleaning processes, and enforcing data quality policies and standards. Additionally, these tools facilitate stakeholder collaboration and communication by enabling workflow management, task assignment, and approval workflows.
Cons
Cost
Data quality tools often involve licensing fees, subscription costs, or implementation expenses, which can represent a significant investment for organizations. The total cost of ownership (TCO) may include upfront licensing costs, ongoing maintenance fees, and expenses associated with customization, integration, and training. For small or budget-constrained organizations, acquiring and deploying data quality tools may be prohibitive.
Vendor lock-in
Adopting proprietary data quality tools may result in vendor lock-in, limiting organizations’ flexibility and autonomy. Once organizations have invested in a specific data quality tool, switching to alternative solutions can be challenging and costly.
Customization and extensibility
While data quality tools offer a range of built-in functionalities, they may lack flexibility for customization and extensibility. Users may need help implementing complex or domain-specific cleaning rules that are not supported out-of-the-box.
Learning curve
Although data quality tools feature user-friendly interfaces, users must familiarize themselves with the tool’s functionalities, workflows, and best practices. Users may need more training or seek assistance from vendor-provided resources to maximize their proficiency with the tool. Moreover, transitioning from traditional data cleaning approaches to data quality tools may require a mindset shift and cultural change within the organization.
Performance overhead
While data quality tools offer scalability and performance optimizations. They may introduce overhead compared to manual or code-based data cleaning approaches. The abstraction layers, graphical interfaces, and additional processing logic in data quality tools can affect performance. This is especially true for real-time or latency-sensitive applications. Organizations should evaluate the performance characteristics of data quality tools under various scenarios and workload conditions. To ensure they meet their performance requirements and service level agreements (SLAs).
Conclusion
Both “Python vs. Data Quality Tools for Data Cleaning” approaches have their merits and are suited to different scenarios. Python offers greater flexibility and customization for cleaning data. It is ideal for data scientists and analysts who prefer code-based solutions and require fine-grained control over the cleaning process. On the other hand, data quality tools provide a more user-friendly and automated experience. It empowers business users and data stewards to perform data cleaning tasks without extensive programming knowledge.
The choice between Python vs data quality tools for data cleaning hinges on several factors. These include the complexity of the data, the users’ expertise, and the specific requirements of the cleaning process. Data quality tools stand out due to their flexibility and scalability. They enable automation and allow business users to effectively carry out data tasks.
{kind=link}