
Image by Carlos Ngaba from Pixabay
Contextualize your business data with content orchestration techniques
One of the major issues enterprises have is tapping into business information that’s trapped in many different siloed applications. Customer data platforms (CDPs) are supposed to unify structured data about customers from a number of these siloed applications and make that information accessible to a broad range of users.
But what about content? Textual content because it behaves differently in digital form is disconnected from images and video, which are in turn disconnected from customer transactional data.
According to Michael Andrews, an independent consultant and former content strategist at Kontent.ai, more advanced, API-centric enterprises could work across all of these silos, orchestrating both content and data resources so they could be custom assembled and delivered to a range of different external and internal consumers.
Such a metasystem or “system of systems” can harness content and data teams together to solve internal business issues as well as improve customer outreach.
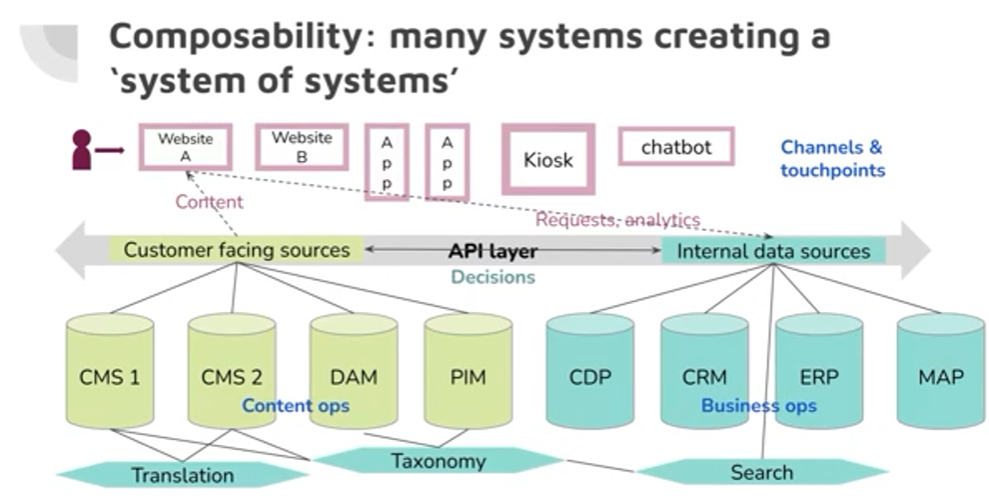
Michael Andrews, 2024. Used with permission.
Devil in the orchestration details
Andrews gave a talk entitled “Understanding The Need For Content Orchestration” in May 2024. Content Wrangler Scott Abel hosted the Brighttalk event. Andrews underscored that content orchestration is not easy, and that a product taxonomy, for example, needs to be designed to work across multiple systems.
That’s an understatement. Really what’s needed for cross-enterprise content + structured data orchestration at scale is a tiered grouping of ontologies and taxonomies that disambiguate and connect the different business contexts in a logically consistent way. You need these levels of abstraction to work across described contexts. If you want visibility across the supply chain, it’s even more important to design your knowledge graph to be logically consistent, subgraph by subgraph.
Take the challenge of industry and product segmentation, for example. It’s easy to get off on the wrong track when just working with established taxonomies that have been in use for years.. Ex-corporate planner Alan Michaels of Industry Building Blocks LLC (IBB) has worked for years on addressing such a problem. Michaels developed an industry + product taxonomy based on Michael Porter’s Five Forces classification approach that’s designed to fix the problems with the North American Industry Classification System (NAICS).
If you stay with NAICS, it’s not possible to get a clear, consistent, up-to-date picture of what products and services the companies are selling because of this misguided, thoroughly inconsistent classification scheme. If you’re trying to forecast demand for your products and assess the competitive marketplace for those products, you’ll encounter frequent misalignment. You’ll be comparing apples to oranges.
Whoever tries to use NAICS either decides not to use it, or uses it with all its flaws and suffers the consequences. What’s worse is that NAICS, through the people who do end up using it, misleads the business public at large every day, at scale.
Michaels became interested in ontologies and web semantics as a means of logically connecting and scaling data contexts across industries and supply networks. I introduced him to Dave McComb at Semantic Arts, whose team developed and built IndustryKG, an RDF ontologized evolution of IBB’s taxonomy. IndustryKG is now commercially available. (Full disclosure: I have a working relationship with Semantic Arts.)
It’s my firm belief that the only way to effectively orchestrate the content and structured data resources of organizations is to take the same approach that IndustryKG embodies, with all data and content you intend to share, period. If your data, structured or unstructured, isn’t logically and consistently connected, it can’t be readily useful as a shared resource.
How organizations can undermine their own orchestration efforts
The existing software in a typical organization’s portfolio presents a serious issue: it tends to reinforce organizational silos with data silos and code fragmentation that themselves echo and perpetuate those silos. In the case of Andrews’ composable metasystem illustration, customer-facing systems and business operations systems are managed by different departments.
Large enterprises have content, knowledge management and data management managed separately. Software that manages information resources most often is designed to handle content, or structured data separately; not both. Software is most often designed to divide and conquer, rather than unify.
Teams responsible for orchestration have to work across these departments. They have to deal with the data and content cartels of the kind that prosper under passive leadership. Orchestration initiatives will often suffer delays resulting from attempts to gain access permission to content and data repositories.
In an era when the demand to mine useful data and content is rising sharply, most leadership is still investing in software as a service that perpetuates old ways of working by increasing data siloing and logic fragmentation. A well-designed application programming interface (API) layer can be helpful, but leadership is working at cross purposes if they blindly incur a higher integration tax year after year by adding more application suites. (See “Ten reasons organizations pay more in data integration tax every year at https://www.datasciencecentral.com/ten-reasons-organizations-pay-more-in-data-integration-tax-every-year/ for more information.)
In that sense, the need for orchestration becomes yet another argument for fundamental data layer transformation. Fundamental transformation tackles the organizational issues, the architectural shortfalls and the data and content problems holistically.
{kind=link}