
Summary: Here’ a proposal for real ‘zero touch’, ‘set-em-and-forget-em’ machine learning from the researchers at Amazon. If you have an environment as fast changing as e-retail and a huge number of models matching buyers and products you could achieve real cost savings and revenue increases by making the refresh cycle faster and more accurate with automation. This capability likely will be coming soon to your favorite AML platform.
 Is there a future in which we can really ‘set-em-and-forget-em’ machine learning? So far Automated Machine Learning (AML) is delivering on vastly simplifying the creation of models but the maintenance, refresh, and update still require manual intervention.
Is there a future in which we can really ‘set-em-and-forget-em’ machine learning? So far Automated Machine Learning (AML) is delivering on vastly simplifying the creation of models but the maintenance, refresh, and update still require manual intervention.
Not that we’re trying to talk ourselves out of a job. But after all, once the model is built and implemented it’s more fun to move on to the next opportunity. If the maintenance and refresh cycle could be truly automated that would be a good thing.
Much of the effort so far has been put into simplifying getting the model out of its AML environment and into its production environment. Facebook’s FBLearner is an example of this. A number of platforms claim to ease this process for the rest of us. At least once we manually refresh the model it’s easier to update it in production.
But the real goal is ‘zero-touch’, the fully automated monitoring, retraining, and implementation of updated models. Last year, Tom Diethe, Tom Borchert, Eno Thereska, Borja Balle, and Neil Lawrence, all of Amazon proposed a reference architecture for making this so. Most of what you’ll read here is described in their paper.
By the time you read this it’s likely that Amazon already has its proprietary version in place and before long this could be a regular feature of AML platforms.
Amazon is a likely first mover in this. They have zillions of different recommender models that are constantly ingesting streaming data about our clicks and purchases. As the offerings and attention in the retail world evolve their models probably drift out of optimal performance more often than most.
If you’re working in an environment of say next-best-offer where your services change more slowly (think financial services), you still need to be vigilant but probably not with the intensity and speed required of on-line retailers.
This highlights the point that the best applications of any potential zero-touch (or auto-adaptive system as the authors put it) will be in a streaming data environment. Here you have the twin challenges of data quality as well as prediction accuracy. Let’s start with an overview of the authors’ proposed architecture.
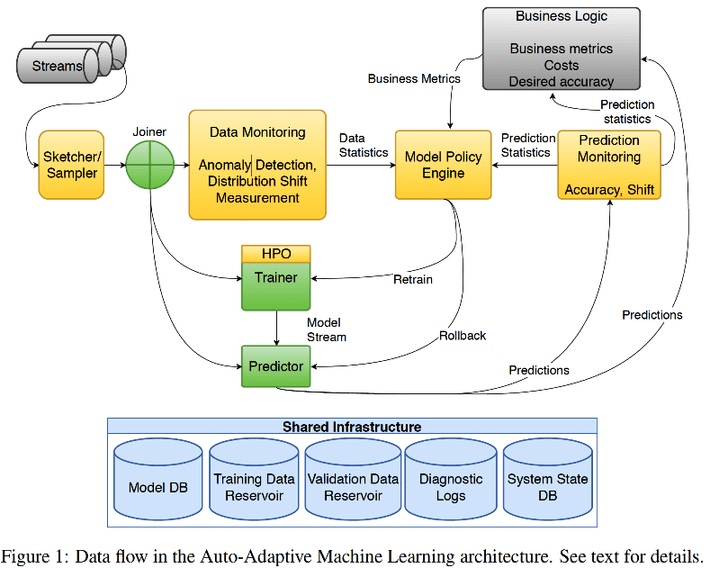
On the left as the streams enter you need a Sketcher/Sampler and Joiner. The Sampler continuously downloads new modeling data for the potential refresh. The Joiner accounts for the real world issues that in streaming data related events may not arrive at the same instant and need to be matched up before they are valuable to process.
The two major operating subsystems are the ‘Data Monitor’ and the ‘Prediction Monitor’.
The Data Monitor focuses on detecting and correcting anomalies, shifts in measurement, or on distributions that are different from our original creation of the model. Reporting out of this module should include the type and magnitude of any shift and the quantification of the resulting uncertainty. If for example, the most predictive variables have shifted rank, that could trigger a complete remodel and review of hyperparameter optimization (HPO). Less significant shifts might warrant just a reweighting of variables.
For the most part these can be sufficiently adjusted in the flow so the process is not disrupted. Really severe departures from what was expected would most likely be kicked out for review by the data science team.
The Prediction Monitor keeps track of model accuracy and tells us if an automated update created by this system is OK to use. Prediction monitoring is reasonably well developed at this point and obviously is designed separately for each model or prediction type.
The heart of the system is the Policy Engine which embeds the business rules and tests about required accuracy balanced against how often the model should be updated and the balance of costs versus potential benefits. Other considerations would include:
Time horizon: How quickly does the new data need to become part of the model (think fast changing retail). How long does it take for new data to become relevant.
What’s the provenance of the data. Extensive detailed logging will be needed to analyze any errors that occur.
The authors suggest that this might eventually be automated with Reinforcement Learning but that’s not currently the case.
Watch for this capability to become a regular part of AML platforms in the near future.
Additional articles on Automated Machine Learning, Automated Deep Learning, and Other No-Code Solutions
Automated Machine Learning for Professionals – Updated (August 2019)
Thinking about Moving Up to Automated Machine Learning (AML) (July 2019)
Automated Machine Learning (AML) Comes of Age – Almost (July 2019)
Practicing ‘No Code’ Data Science (October 2018)
What’s New in Data Prep (September 2018)
Democratizing Deep Learning – The Stanford Dawn Project (September 2018)
Transfer Learning –Deep Learning for Everyone (April 2018)
Automated Deep Learning – So Simple Anyone Can Do It (April 2018)
Next Generation Automated Machine Learning (AML) (April 2018)
More on Fully Automated Machine Learning (August 2017)
Automated Machine Learning for Professionals (July 2017)
Data Scientists Automated and Unemployed by 2025 – Update! (July 2017)
Data Scientists Automated and Unemployed by 2025! (April 2016)
Other articles by Bill Vorhies
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 2 million times.
He can be reached at:
{kind=link}