
Building accurate models takes a great deal of time, resources, and technical ability. The biggest challenge? You almost never know what model or feature combination will end up working.
Like many others, I was having to spend painstaking amounts of time preparing data for a specific algorithm and then developing all the code and processing for that algorithm just to find out that it doesn’t train well on my data or I didn’t have the right features. Tasked with creating consistent and profitable trading models for financial currency markets, I struggled with getting the right balance of model and features until I discovered the Sagemaker/Essentia pipeline.
Exploring the Pipeline
What I found useful about the pipeline is that a lot of my work was either done for me or was able to be implemented quickly. Sagemaker provided the sample scripts and ready-to-run algorithms to try machine learning / deep learning on my data quickly while Essentia handled the actual data preparation and feature enhancement.
Both parts of this pipeline were fully scalable across multiple EC2 instances and I was able to both train models as well as restart my run with new features extremely quickly. This helped a great deal since there were countless feature combinations I could try and many different volatile patterns that needed to be detected.
Feature Engineering and Model Selection
Starting with an initial model that I had created through various machine learning methods and exploration using PivotBillions and R, I used Essentia to setup my data to contain multiple features across 10 years of data. Then I had Essentia enhance the data to contain a 100 minute history of each feature for each signal in my original model.
After exploring some of the algorithms on Sagemaker, I finally settled on using the XG Boost algorithm for its ability to pick up many interactions between a great deal of feature subsets. This seemed helpful since it could look across my features as well as look into the many smaller interactions over time by looking at the feature histories.
Hyper Parameter Tuning and Results
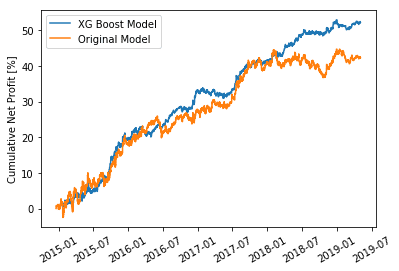
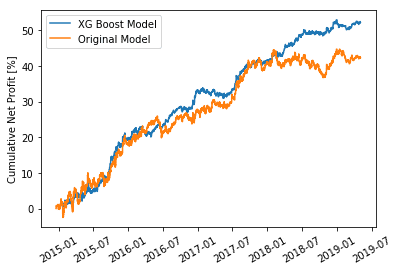
My first training showed some improvement in the training/validation metric but did not translate into smoother or greater profit. So I made use of Sagemakers’ Hyper Parameter Tuning ability to narrow in on better XG Boost parameters for my financial data. After just a few runs it quickly came back with the best performing Hyper Parameters from its search. Utilizing these parameters in the XG Boost algorithm and testing on my hold-out set I was able to achieve a much smoother model that also achieved greater profitability.
{kind=link}