
Azure Machine Learning concepts – an Introduction
Introduction
Last week, we launched a free book called Classification and Regression in a weekend. The idea of the ‘in a weekend’ series of books is to study one complex section of code in a weekend to master the concept. This week. we plan to launch a book called “An Introduction to Azure Machine Learning in a Weekend”. This blog relates to the forthcoming book. If you don’t have an Azure subscription, you can use the free or paid version of Azure Machine Learning service. It is important to delete resources after use.
Azure Machine Learning service is a cloud service that you use to train, deploy, automate, and manage machine learning models – availing all the benefits of a Cloud deployment.
In terms of development, you can use Jupyter notebooks and the Azure SDKs. You can see more details of the Azure Machine Learning Python SDK which allow you to choose environments like Scikit-learn, Tensorflow, PyTorch, and MXNet.
Sequence of flow
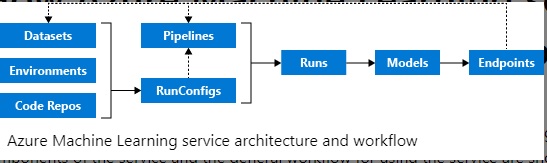
Source: https://docs.microsoft.com/en-gb/azure/machine-learning/service/ove…
The Azure machine learning workflow generally follows this sequence:
- Develop machine learning training scripts in Python.
- Create and configure a compute target.
- Submit the scripts to the configured compute target to run in that environment. During training, the scripts can read from or write to datastore. And the records of execution are saved as runs in the workspace and grouped under experiments.
- Query the experiment for logged metrics from the current and past runs. If the metrics don’t indicate a desired outcome, loop back to step 1 and iterate on your scripts.
- After a satisfactory run is found, register the persisted model in the model registry.
- Develop a scoring script that uses the model and Deploy the model as a web service in Azure, or to an IoT Edge device.
Below, we explain some concepts relating to running machine learning algorithms in the Azure Cloud as per the above flow
The workspace is the top-level resource for Azure Machine Learning service. It provides a centralized place to work with all the artefacts you create when you use Azure Machine Learning service. The workspace keeps a history of all training runs, including logs, metrics, output, and a snapshot of your scripts.
Once you have a model you like, you register it with the workspace. You then use the registered model and scoring scripts to deploy to Azure Container Instances, Azure Kubernetes Service, or to a field-programmable gate array (FPGA) as a REST-based HTTP endpoint. You can also deploy the model to an Azure IoT Edge device as a module.
When you create a new workspace, it automatically creates several Azure resources that are used by the workspace:
- Azure Container Registry: Registers docker containers that you use during training and when you deploy a model.
- Azure Storage account: Is used as the default datastore for the workspace
- Azure Application Insights: Stores monitoring information about your models.
- Azure Key Vault: Stores secrets that are used by compute targets and other sensitive information that’s needed by the workspace.
An experiment is a grouping of many runs from a specified script. It is always associated to a workspace.
A model: has the same meaning as in traditional machine learning. In Azure, a model is produced by a run but models trained outside Azure can also be used. Azure Machine Learning service is framework agnostic i.e. popular machine learning frameworks such as Scikit-learn, XGBoost, PyTorch, TensorFlow etc can be used.
The model registry keeps track of all the models in your Azure Machine Learning service workspace.
A run configuration is a set of instructions that defines how a script should be run in a specified compute target. The configuration includes a wide set of behavior definitions, such as whether to use an existing Python environment or to use a Conda environment that’s built from a specification
Azure Machine Learning Datasets manage data in various scenarios such as model training and pipeline creation. Using the Azure Machine Learning SDK, you can access underlying storage, explore and prepare data, manage the life cycle of different Dataset definitions, and compare between Datasets used in training and in production.
A datastore is a storage abstraction over an Azure storage account. The datastore can use either an Azure blob container or an Azure file share as the back-end storage. Each workspace has a default datastore, and you can register additional datastores. You can use the Python SDK API or the Azure Machine Learning CLI to store and retrieve files from the datastore.
A compute target is the compute resource that you use to run your training script or host your service deployment. Your local computer, A linux VM in Azure; Azure Databricks etc are all examples of compute targets
A training script – brings it all together. During training, the directory containing the training script and the associated files is copied to the compute target and executed there. A snapshot of the directory is also stored under the experiment in the workspace.
A run – A run is produced when you submit a script to train a model. A run is a record that contains information like the metadata about the run, output files, metrics etc
Github tracking and integration – When you start a training run where the source directory is a local Git repository, information about the repository is stored in the run history.
Snapshot – snapshot(of a run) represents compressed directory that contains the script as a zip file maintained as a record. The snapshot is also sent to the compute target where the zip file is extracted and the script is run there.
An activity represents a long running operation. Creating or deleting a compute target. Running a script on the compute target etc are all examples of activities.
Image Images provide a way to reliably deploy a model, along with all components you need to use the model. An image contains of a model, scoring script or application and dependencies that are needed by the model/scoring script/application
Azure Machine Learning can create two types of images:
- FPGA image: Used when you deploy to a field-programmable gate array in Azure.
- Docker image: Used when you deploy to compute targets other than FPGA. Examples are Azure Container Instances and Azure Kubernetes Service.
Image registry: The image registry keeps track of images that are created from your models. You can provide additional metadata tags when you create the image.
Deployment
A deployment is an instantiation of your model into either a web service that can be hosted in the cloud or an IoT module for integrated device deployments.
Web service: A deployed web service can use Azure Container Instances, Azure Kubernetes Service, or FPGAs. You create the service from your model, script, and associated files. These are encapsulated in an image, which provides the run time environment for the web service. The image has a load-balanced, HTTP endpoint that receives scoring requests that are sent to the web service.
Iot module: A deployed IoT module is a Docker container that includes your model and associated script or application and any additional dependencies. You deploy these modules by using Azure IoT Edge on edge devices.
Pipelines: You use machine learning pipelines to create and manage workflows that stitch together machine learning phases. For example, a pipeline might include data preparation, model training, model deployment, and inference/scoring phases. Each phase can encompass multiple steps, each of which can run unattended in various compute targets.
Conclusion
We hope that this blog provides a simple framework to understand Azure. The blog is based on the Azure documentation here.
{kind=link}