

The US Securities and Exchange Commission (SEC), which regulates public company securities, recently proposed its own climate impact reporting requirement. Many US public companies already voluntarily publish information on this topic for shareholders who have been asking for those details. But various state GOP attorneys general are already questioning the SEC’s ability to impose the requirement, asserting that such a requirement lacks materiality.
So there’s a distinct possibility the SEC’s proposal will get tied up in litigation, at least for now. Back in September 2021, Addisu Lashitew, nonresident fellow, global economy and development at The Brookings Institution, characterized the US stance on the climate impact reporting issue as laissez faire.
The US may well continue to be laissez faire on this issue at least through 2022. But one could imagine legislators from blue states countering what’s being blocked in red states with their own requirements. California, for example, has often led the rest of the nation on regulation. Companies who have business in California must comply with California law, of course. Would California just pass its own law, given that the SEC and other Federal agencies may have their hands tied indefinitely? The State of California, after all, did pass and enact its own data protection law, the California Consumer Privacy Act, or CCPA, beginning in 2018.
Meanwhile, the European Union is moving ahead on what it is now calling the sustainability reporting front. The European Parliament in March prepared amendments to the nine-year old Directive 2013/34/EU. Among other things, the amendments tighten up guidelines so that climate impact/sustainability reports will be more comparable company to company. They also clear a path for a broader range of environmental testing and audit providers to help companies comply with the revised Directive.
Best to be prepared to take on the challenge of this kind of compliance, regardless of how it materializes.
The regulatory compliance challenge: Escalating cost and RegTech myopia
Public enterprises spend $ billions on regulatory compliance that demands different kinds of reporting, much of it financial. After the subprime mortgage crisis in 2007-9, for example, regulators became a lot more aggressive about demanding frequent or even real-time reporting on derivatives trades. Those demands triggered both an open ontology–flexible, evolving graph data model–development effort and a global financial instrument identifier effort.
And anti-money laundering compliance spending on its own is huge, with each big bank spending as much as $1B a year or more on compliance. Now that so many countries have announced sanctions and seizing assets in response to the invasion of Ukraine, providing visibility into cause and effect and how money laundering customers and providers are connected are even more important.
Both public securities market regulation and anti-money laundering regulation have increased enterprise interest in knowledge graphs. A resulting problem is that demand for knowledge graphs is now outstripping supply. Good ontologists, knowledge architects and engineers are as scarce as hens’ teeth. Another issue is that companies may have tried to build their own knowledge graphs, but have failed.
Which leaves often less tech savvy corporate governance, risk and compliance execs vulnerable to RegTech pitches from far and wide.
The more interdependent business gets across jurisdictional boundaries, the more compliance requirements are bound to grow. Enterprises are forced to become more cost-effective and efficient about the reporting they have to do. Ideally, they’d decide to build a reporting environment once that can be used many times over regardless of the reporting regulation that emerges.
Build one evolving, shared resource, rather than buying one tool after another
IMHO, most enterprises take a shallow approach to digital transformation. They do so because the people who are responsible for automation and compliance aren’t really focused on the data layer. Most folks aren’t like Data Science Central readers–they take an application-centric view. At its worst, such a view dooms compliance teams to reinvent the wheel every time a government agency imposes a new regulatory compliance requirement.
How do enterprises avoid reinventing the wheel? As discussed in previous posts, the transformation needs to be architectural, not just a band-aid approach. To begin with, architecture needs to be turned on its head so that data comes first.
Enterprises will need to base their compliance initiatives on data-centric principles, so that systems-level transformation can address a broad range of both existing and new reporting requirements. The system, in other words, needs to be adaptive and built on a knowledge foundation.
Building an adaptive compliance response with the help of a data-centric or knowledge foundation is the antithesis of most so-called RegTech (for Regulatory Technology). Most RegTech offerings, as far as I can tell, are mimicking the opaque and wasteful way cloud security software is developed and sold.
Companies migrating to the cloud feel like they have to take their security tooling with them, because they can’t find out if what’s available from the cloud provider does what the old tool used to do or not. Meanwhile, both the cloud service and third-party providers continue to build and offer new tools targeting specific problems. It’s impossible to keep up with what tool does what, how well it does it, or how comprehensive it is. Is it a true replacement, or not?
Meanwhile, migrating to the cloud isn’t evidence of transformation. (See Is Old Data Strategy Drowning New Data Strategy? for a take on what constitutes bona-fide data strategy and transformation.)
Shared resources are becoming much more important. If companies build consortia and a unified reporting environment using a shared knowledge graph approach, they could build once and use everywhere because of the inherent scalability of the technology.
This shared resource focus triggered the single knowledge graph for consortium multimedia knowledge sharing and search approach of Blue Brain Nexus, a global community of academic researchers and scientists focused on reverse engineering the brain.
The Blue Brain effort open sourced the knowledge graph building method that the academics use and opened the environment to those who had something relevant to share. The unified shared graph can grow, subgraph by subgraph.
Knowledge graphs can make reporting cost effective and efficient
Back in 2009, the CEO of a now defunct startup I interviewed told me he had solved a reporting problem for a major pharmaceutical enterprise. The challenge was, how do you reduce the time it takes to collect periodic reports from the department level, validate and aggregate them? He told me the startup had solved the problem with semantic technologies–a knowledge graph, in other words. This was years before Google coined the term knowledge graph. He and his company were too early, apparently.
Then, in 2015, PwC worked with Hewlett-Packard (now HPE) to reduce reporting preparation time from 24 hours to 7 minutes. PwC used five people who took 150 man days to enable the more efficient process. PwC then piloted EnterpriseWeb to work on the same challenge, to compare PwC’s own method with EW’s. EW used one person, who took four hours to reduce reporting process time to less than ⅓ of a second.
EW went on to gain adherents in the telecom industry, where network function virtualization (NFV) has become a big deal and many of the solutions proposed were not up to the task. The challenge NFV proposed to tackle was how to scale. The management of configurability changes. EW uses software agents to handle configuration changes. Their method is far more strategic than robotic process automation when it comes to process optimization.
Here’s how the platform worked back in 2015:
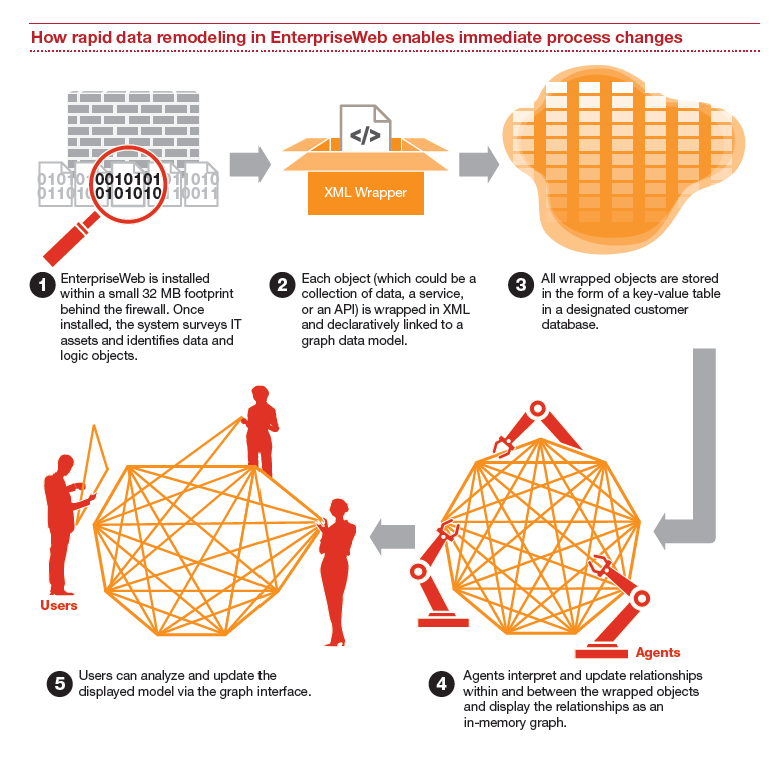
EnterpriseWeb and PwC, 2015
Consider the digital switches and all of the other equipment assets that cellular, other wireless, fiber optic and landline networks have to deal with. A flexible form of automation can help reduce management costs considerably across all network types and across an entire industry.
Interestingly, the very same technology that helped HP streamline and reduce reporting time so radically is also effective on the configuration management front also. Supply chains involving players from many different industries can take advantage of the same approach.
Taking a different tack on dashboarding and periodic reporting
The US SEC and public companies together invested years in building a shared resource before–standard financial reporting. Key to the effort back then was XML and a dialect called XML Business Reporting Language (XBRL).
Once it kicked in earnest in the 2010s, XBRL became a success, and costs of compliance decreased. XBRL filing costs for smaller companies declined from an average of $10,000 in 2014 to $5,476 in 2017.
The next phase of this evolution involves broader business reporting, more scalable, knowledge rich semantic graphs and the move to a flow from a batch paradigm for reporting. The semantic graph foundation (along the lines of standards like the W3C’s) is designed to be open and shared.
The more companies get on board with the most scalable and knowledge-rich approach, the more reporting costs per compliance requirement can go down. But for this to happen, leadership needs to know about it, and the community as a whole needs to explain better the challenges, solutions and benefits to business in simple terms that articulate what needs to happen for “digital transformation” to become bona fide, foundational, data-centric transformation.
{kind=link}