

The Harvard Business Review article “Has Generative AI Peaked?” raised a troubling concern concerning Generative AI (GenAI):
“This brings us to an unsettling yet entirely conceivable prospect: Future AI models might predominantly train on their own outputs. Could such a model genuinely capture the nuances of human thoughts and behavior? It appears inevitable that this cycle of inbreeding will bring about a bland AI echo chamber.
This is not just speculation. A recent study showed that training models based on data from other generative AI models lead to an irreversible, degenerative process. The final model overestimates probable events while underestimating improbable ones, eventually losing touch with the actual data distribution. Importantly, this phenomenon, termed “model collapse,” is seen across different model types, from LLMs to image generators, and it takes only a few generations for the outputs to become useless.”
A critical flaw in how GenAI and LLM models are developed and managed threatens to undermine their efficacy and trustworthiness. As Large Language Models (LLMs) are continuously updated with data derived from GenAI tools, there is a growing tendency to generate recommendations based on averages. While these averages can provide a generalized understanding, they inherently gloss over the nuances and specificities often crucial in real-world applications.
Death By “Regression to the Mean”
The danger lies in the inherent nature of averages to dilute outliers and exceptional cases, which are often the key drivers of innovation and strategic differentiation. By relying too heavily on historical data, GenAI tools risk perpetuating existing biases and overlooking emerging trends that still need to fit into the established patterns. This can lead to a homogenization of insights and recommendations, stifling creativity and potentially steering businesses toward mediocrity. While averages provide a safe middle ground, they may also blind us to the unique opportunities and risks at the fringes of our data landscapes.
Moreover, as these models are increasingly adopted across various sectors, the reliance on historical averages could have far-reaching implications.
- In healthcare, relying on averages could result in ineffective treatment plans for patients with uncommon conditions or unique genetic profiles.
- In financial markets, investment strategies based on overly generalized historical data may fail to predict or adapt to unprecedented economic events, leading to substantial financial risk.
- Reliance on recursively trained models in the justice system could result in biased judgments, as the models might need to pay more attention to nuanced legal precedents or unique case details.
- In education, AI-driven personalized learning tools might become less effective by failing to accommodate diverse learning styles and needs, instead promoting a one-size-fits-all approach that neglects individual student differences.
This over-dependence on building GenAI models based on historical averages can lead to “death by regression to the mean,” where the inherent potential of GenAI tools to drive creativity and innovation gets averaged out. Instead of generating groundbreaking insights and fostering novel solutions, these tools begin to produce safe, predictable, and mediocre outputs. The unique cases that often spark innovation are diluted, and the focus shifts to maintaining the status quo rather than pushing boundaries. As a result, the transformative power of GenAI is significantly undermined, leading to a stagnation in progress and a missed opportunity to leverage AI’s full potential for creative and innovative breakthroughs across various industries.
Degenerative Model Collapse
Degenerative Model Collapse refers to a degenerative learning process where models start forgetting improbable events over time as the model becomes poisoned with its reality projection.
The article “The Curse of Recursion: Training on Generated Data Makes Models Forget” explores the detrimental effects of recursively training models on their generated data. This process, termed “degenerative model collapse,” leads to a degenerative learning cycle where models progressively forget the actual data distribution. This recursive training causes models to lose touch with rare events and outliers, thus simplifying and distorting their understanding of reality over time.
The degenerative model collapse phenomenon occurs when models, over time, start to forget or disregard improbable events as they become increasingly “poisoned” with their reality projections. These models continuously learn from their outputs rather than from diverse new, real-world data, reinforcing a narrowed perspective. This self-reinforcing loop can significantly affect the model’s ability to recognize and respond to rare or novel occurrences.
GenAI tools often function as “regurgitators of the average,” generalizing from broad datasets. However, when input data becomes progressively uniform due to the model’s outputs being fed back into it, the relevance and accuracy of responses can diminish significantly. This degenerative process undermines the model’s capacity to handle outliers or atypical cases, crucial for nuanced decision-making and innovation.

Figure 1: Generative AI Model Collapse Example
Making decisions based on averages of averages is challenging and dangerous, as it obscures true data variability, diversity, and complexity. This approach ignores confounding variables, outliers, and interactions, distorting causal relationships and leading to misleading, inaccurate, or biased decisions. This myopic view can result in wrong or suboptimal decisions across various applications, from healthcare to finance.
Addressing Degenerative Model Collapse
To avoid Degenerative Model Collapse, some actions can be taken by the developers and users of generative models. Some of these actions are (Figure 2):
- Expanding the generative model’s capacity and complexity allows it to create a broader range of outputs. For instance, an e-commerce company could improve its recommendation engine by increasing the model’s layers and neurons, offering more diverse and personalized product suggestions based on subtle user behavior patterns.
- Adjust the generative model’s learning rate and optimization algorithm. This enables the model to learn from different parts of the training data and avoid getting stuck in local minima. For example, a financial institution could adjust its fraud detection model’s learning rate and optimization algorithm to ensure it can learn from a broader range of transaction data, avoiding getting stuck on common fraud patterns and missing new, less obvious ones.
- Using regularization techniques. Techniques such as weight decay or dropout can mitigate overfitting and improve generalization. For instance, a healthcare AI system could apply weight decay and dropout to its predictive model to prevent overfitting historical patient data. This helps improve its ability to accurately predict outcomes for new patients by preventing overfitting and enhancing generalization.
- Utilizing diversity-promoting methods. Techniques such as diversity regularization or introducing noise to the input or output of the generator can improve model effectiveness. For instance, a media streaming service could apply diversity regularization. It introduces noise to the input data of its content recommendation model to guarantee that it suggests a broader range of genres, not just the most popular ones, to accommodate diverse user preferences.
- Validating and verifying the generative model results. Human feedback, external sources, or other methods are essential for validating and verifying the results of the models. For example, a legal tech firm could validate the outputs of its AI-based legal research tool by cross-referencing the generated case summaries with human expert reviews and external legal databases to ensure accuracy and reliability.
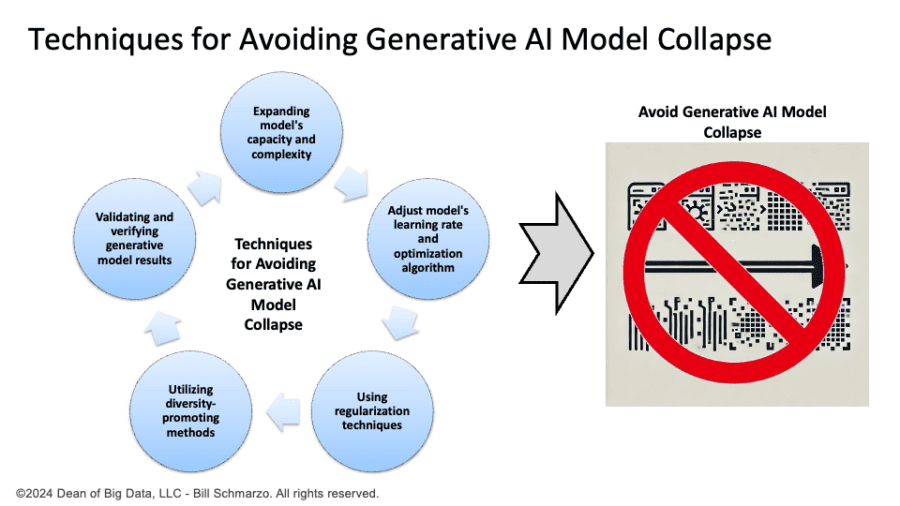
Figure 2: Techniques for Avoiding Generative AI Model Collapse
Data scientists and AI practitioners must maintain a vigilant approach to data diversity and complexity, ensuring that Generative AI models are exposed to various scenarios and edge cases.
Avoiding Generative Model Collapse Summary
Generative AI (GenAI) faces a potentially disastrous issue known as “degenerative model collapse.” This occurs when the models generate recommendations based solely on historical averages, neglecting outliers and exceptional cases crucial for innovation. To mitigate this, we can expand model capacity, adjust learning rates, employ regularization techniques, promote diversity, and validate outputs through human feedback to prevent the Generative AI model “death by regression to the mean.”
{kind=link}