
Summary: There are a variety of new Automated Machine Learning (AML) platforms emerging that led us recently to ask if we’d be automated and unemployed any time soon. In this article we’ll cover the “Professional AML tools”. They require that you be fluent in R or Python which means that Citizen Data Scientists won’t be using them. They also significantly enhance productivity and reduce the redundant and tedious work that’s part of model building.
 Last week we wrote about Automated Machine Learning (AML) and particularly about a breed of platforms that promise One-Click Data-In Model-Out simplicity. These were quite impressive and all but one has been in the market for more than a year, each claiming its measure of success. One of the key characteristics these platforms offer is simplicity that drives two user benefits:
Last week we wrote about Automated Machine Learning (AML) and particularly about a breed of platforms that promise One-Click Data-In Model-Out simplicity. These were quite impressive and all but one has been in the market for more than a year, each claiming its measure of success. One of the key characteristics these platforms offer is simplicity that drives two user benefits:
- The ability for trained data scientists to produce quality supervised models quickly, thereby also reducing cost.
- The at least theoretical capability that these tools could be used by much less experienced or even amateur citizen data scientists dramatically expanding the market for these platforms.
What’s worthy of note however is that there are a number of AML packages that rely exclusively on code, both R and Python, that we want to take a look at this week.
The implication of the fact that they require you to code is that it requires expert professional data scientist skills to execute and therefore does not open them up to use by citizen data scientists. Also these are all open source. Let’s call these Professional AML tools.
So although the user interface is not as ‘slick’, if your organization is an R or Python shop then these packages offer the consistency, speed, and economy of the true One-Clicks.
The Middle Way
In our last articles we also noted a number of platform vendors that had selected “a middle way” by which we mean that while several steps were automated, the user was still required to go through several traditional separate procedures.
This platform simplification is also a good thing and perhaps even superior to fully automated machine learning since it requires the user to examine assumptions and processes at each step. However, for purposes of this article we’re looking for applications that are as close to one-click as we can get.
As it turns out there are a number of code-based open source apps that have been developed that address just one or two features of AML. The most popular of these take on one of the most difficult problems which is hyperparameter tuning. These include:
- Hyperopt
- SMAC and SMAC3 – Sequential Model-based Algorithm Configuration
- RoBO – Robust Bayesian Optimization framework
In addition there is at least one suite of tools, CARET, which although not integrated as one-click, offers a broad range of apps for ‘automating’ many of the separate steps in model creation. CARET is open source in R.
Ideally What They Should be Able to Do:
Certainly there are any number of tasks in the creation of predictive models that are more repetitive than creative. We’d like to be able to delegate tasks that are fundamentally repetitive, things that make us wait and waste our time, and tasks that can be built up from reusable routines.
The commercial applications of AML that we examined in our last article could cover the full process. Here on the ‘Professional Tools’ side we might expect and accept a little less integration. But still we want these tools to be able to combine many of the following steps into a single click task after we provide an analytic flat file:
- Preprocess the data. Including cleansing, transforms, imputes, and normalizations as required. Note that we’ve seen some apps that stick with decision trees and their ensemble variants just because they need so little of this.
- Feature engineering and feature selection. OK, it takes a domain expert to do really effective feature engineering but it ought to at least be able bucket categoricals, create some date analyses like ‘time since’ or ‘day of week’, and create ratios from related features.
- Select appropriate algorithms, presumably a fairly large number of primary types that would be run in parallel.
- Optimize the hyperparameters. The more algorithm types selected the more difficult this becomes.
- Run the models including a loop to create some meaningful ensembles.
- Present the results in a manner that allows simplified but accurate comparison and selection of a champion model.
- Deploy: Provide a reasonably easy method of exporting code or at least an API for scoring and implementation in operational systems.
Limits
If it seems like we’re asking for a lot, and we are, then we should also be specific about what we’re not expecting.
- These should prepare classical supervised learning models of both regression and classification. For now we’d probably settle for just classification.
- We’re not looking for exotic time series models.
- We’re not asking for deep neural nets or unlabeled data (though some of these are starting to emerge). Both the target and the variables should be labeled.
Here are Three Strong Contenders
Auto-sklearn
Auto-sklearn is the most widely mentioned and relatively complete professional AML, especially since it has won or placed well in a variety of recent AML contests. If you already have the python scikit-learn library you can drop in this open source code as a replacement for scikit-learn estimator.
It will handle missing values, categoricals, sparse data, and rescaling with 14 preprocessing methods. It passes off from the preprocessing module to the classifier / regressor including 15 ML algorithms and Bayesian hyperparameter tuning for a total of 110 hyperparameters. It will also automatically construct ensembles.
This diagram showing the scope of Auto-sklearn is drawn from the original 2015 NIPS paper.
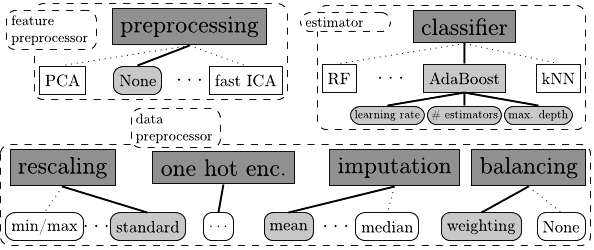
Interestingly Auto-sklearn has been expanded to handle deep neural nets with an add-in package Auto-Net adding this as a 16th ML algorithm.
AutoWEKA 2.0
AutoWEKA was introduced in 2009 and its current enhanced 2.0 version remains one of the most popular AMLs driven by the large existing WEKA user base. It focuses on feature selection, hyperparameter optimization, and ML selection but other WEKA modules provide the means for preprocessing.
- There are a wide range of automated feature selection techniques including 3 search and 8 evaluator methods.
- Classifiers include all 27 of the base WEKA methods including 2 ensemble methods, and 10 meta-methods.
Auto-WEKA 2.0 now also supports:
- Regression
- Optimization of the all performance metrics supported by WEKA.
- Natively supports parallel runs on a single machine saving the N best configurations instead of the just the single best.
- It’s now also fully integrated with WEKA.
Read more about Auto-WEKA 2.0 in this 2016 Journal of Machine Learning article.
TPOT (Tree-based Pipeline Optimization Tool)
TPOT is still under active development but is available today on top of python based scikit-learn. It’s billed as “your Data Science Assistant” to automate the most tedious portions of model development. As its name specifies this is a tree-based classifier only with automation starting after cleaning but through the delivery of production ready python code. This diagram from the TPOT home page shows the scope.
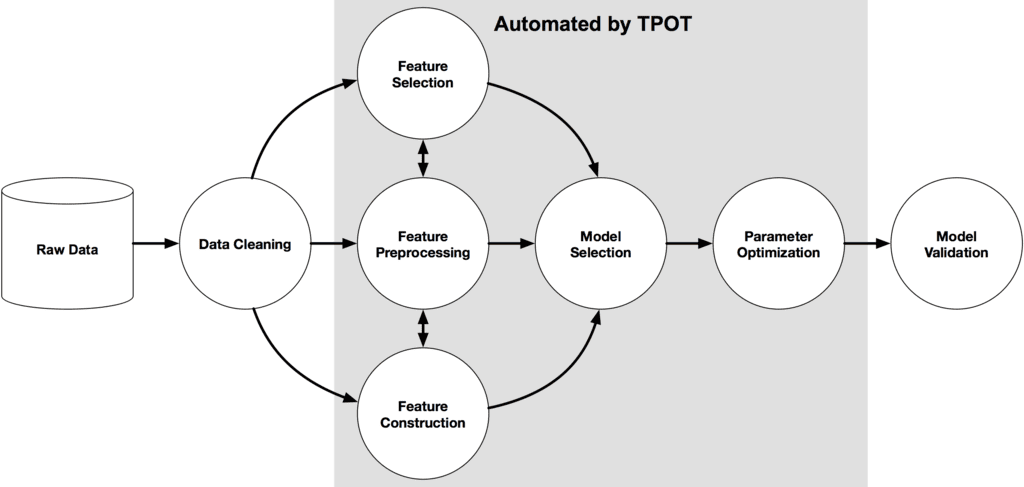
Perhaps TPOT’s most interesting feature is that hyperparameter optimization is based on genetic programming. For the expert user all the assumptions are fully exposed so that you can continue to work the hyperparameters to test the optimization. Read more about TPOT in this 2016 JMLR Conference proceeding.
Finally
Please note that our research for this article is not exhaustive. The packages we’ve discussed here had sufficient mentions to rise to our attention. This is an active area of development and there are likely to be more entrants all the time. The fact is that the shortage and expense of well qualified data scientists is driving this. We need to be sensitive to producing more high quality results with fewer resources and AML, that reduces our most redundant and least creative work is an obvious path.
Additional articles on Automated Machine Learning
Next Generation Automated Machine Learning (AML) (April 2018)
More on Fully Automated Machine Learning (August 2017)
Data Scientists Automated and Unemployed by 2025 – Update! (July 2017)
Data Scientists Automated and Unemployed by 2025! (April 2016)
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at:
{kind=link}