
Social media platforms such as Twitter and Facebook enable everyone to voice their opinions about topics, companies, and products online.
These comments are a great source for companies to analyze their customers’ opinion about their brand or product. However, with billions of Tweets and posts daily, this is can take a lot of time.
Unless of course, you use R J With just a few lines of R-code and the help of machine learning, we’re able to build mood monitoring tools quickly, so that the public opinion about your or anyone’s company can be monitored and evaluated.
Opinions on a brand over time
The aim of our script is to analyze the opinions about individual companies over a longer period of time. In order to get an “opinion” we decided to analyze the mood on Twitter. The airline AirBerlin, which had to file for bankruptcy only a few weeks ago, is a good example.
So we have our channel: Twitter and our brand: AirBerlin. Now it’s time to collect their users’ opinions.
The problem with the Twitter API
Twitter offers a free API that return on a specific topic (and other filtering options) returned to them. In addition, there is a very good package called “TwitteR” for this API, which makes querying the data extremely easy. It is only necessary to create an API project.
Unfortunately, the Twitter API has a disadvantage, which is that we only get data from the last seven days. The API is therefore not suitable for long-term monitoring. The Twitter interface, on the other hand, gives us all Tweets. They can be reached through the “Advanced Search” on Twitter, which can be found in the right sidebar of the Twitter-SERPs. The options for finding tweets are almost unlimited.
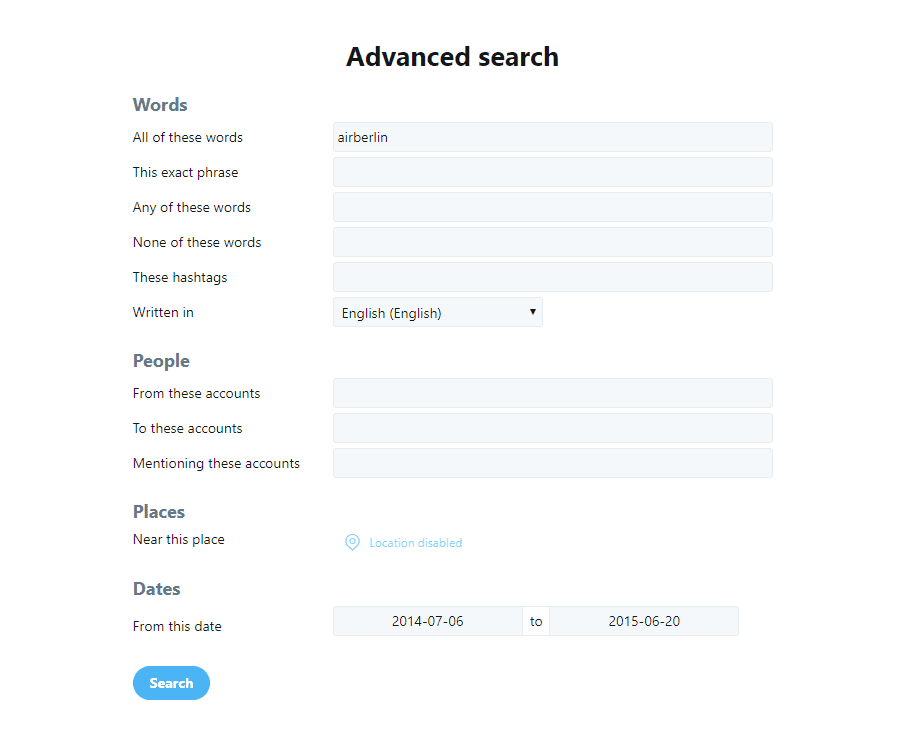
In addition, the URL of the search results filtered by Advanced Search contains the individual filter settings. That makes crawling the results very easy:
https://twitter.com/search?l={{LANGUAGE}}&q={{SEARCH_TERM}}20since%{{START_DATE}}until%3A{{END_DATE}}&src=typd
Building the Selenium Crawler
To get to the Tweets, we had to build a crawler that calls the corresponding URL and saves the Tweet. In order to obtain a broad range of opinions, we randomly query 50 selected Tweets every week since 2013.
driver<- rsDriver(browser = c(“firefox”))
remDr <- driver[[“client”]]
remDr$navigate(“https://twitter.com”)
#Log IN
#Get Tweets
out<-capture.output(for (i in 1:nrow(Start_End)){
page<-paste0(“https://twitter.com/search?l=de&[email protected]%20since%3A”,Start_End$Start_date[i],”%20until%3A”,Start_End$End_Date[i],”&src=typd”)
remDr$navigate(page)
Sys.sleep(5)
try(webElem <- remDr$findElements(using = “css”, ‘.tweet-text’))
for (a in 1:20){
w<-try(webElem[[a]])
messages[[a]]<-try(w$getElementText())}
m<-as.data.frame(do.call(rbind, messages))
print(m)
Sys.sleep(5)
})
The code gives us the following output:

How to generate a training set
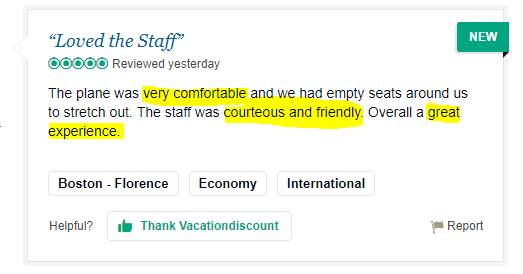
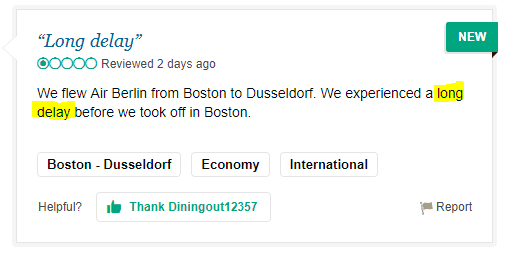
Now that we have collected a nice set of user reviews over 4 years, we have to qualify them. So we had to find a suitable training set. Fortunately, the number of flight / travel / hotel rating sites is vast. The fact that the users have an asterisk rating next to a qualifying text makes it easy to create a clean and structured set.
In the reviews we find combinations of words which are frequently used in good ratings (e. g. very comfortable, friendly, etc.) or bad ratings (e. g.”long delay”, etc.). Based on this our system can learn what is perceived as positive or negative by people on flights.
Easier Method: Bing Cognitive Services
There are some areas where it is extremely easy to assemble a nice learning set. For example, airlines, hotels, etc. have a large number of user voices on the net, which often come with a rating in addition to the pure text rating. In other areas, this can prove to be much more difficult.
Text analysis from Microsoft Cognitive Services is a good alternative. You give the API text segments and get a mood index in return. In the free plan you have 5000 API calls per day.
The following code snippet allows you to evaluate the individual tweets via the Microsoft API.
score<-NULL;
score<-capture.output(for (i in 1:5000){
q<-Tweets$X1[i]
request_body <- data.frame(
language = c(“de”,”de”),
id = c(“1″,”2”),
text = out[[q]])
request_body_json <- toJSON(list(documents = request_body), auto_unbox = TRUE)
result <- POST(“https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/sentiment”,
body = request_body_json,
add_headers(.headers = c(“Content-Type”=”application/json”,”Ocp-Apim-Subscription-Key”=”YOUR_KEY”)))
Output <- content(result)
print(Output$documents[[1]]$score)
Sys.sleep(0.5)
})
The output for Air Berlin
For AirBerlin, we analyzed just under 10,000 tweets over a period of 4.5 years and summarized the results on a monthly basis. This is the result:
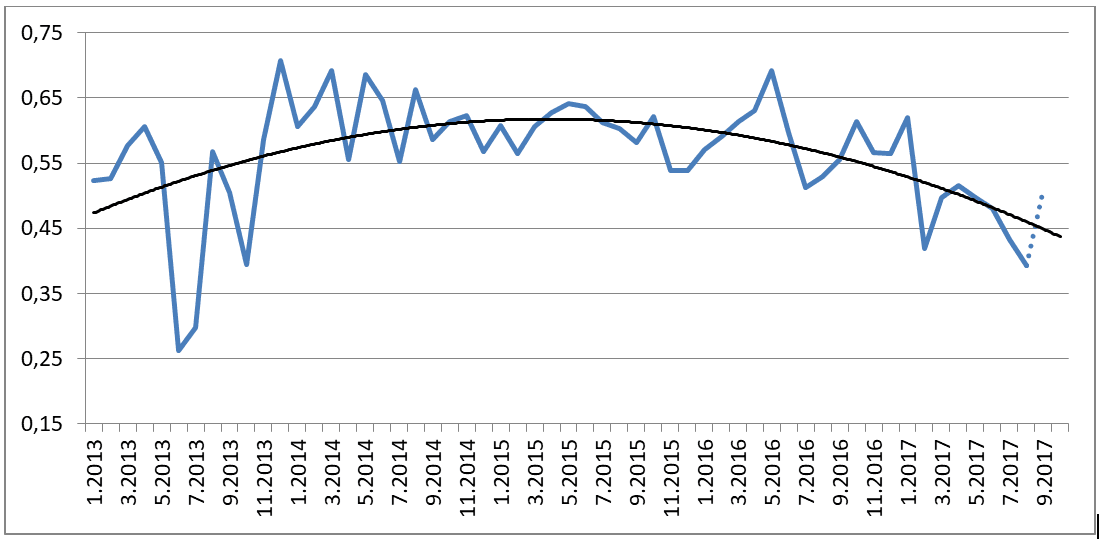
On the timeline, we added some major events to see how and if they have affected opinions on the web.
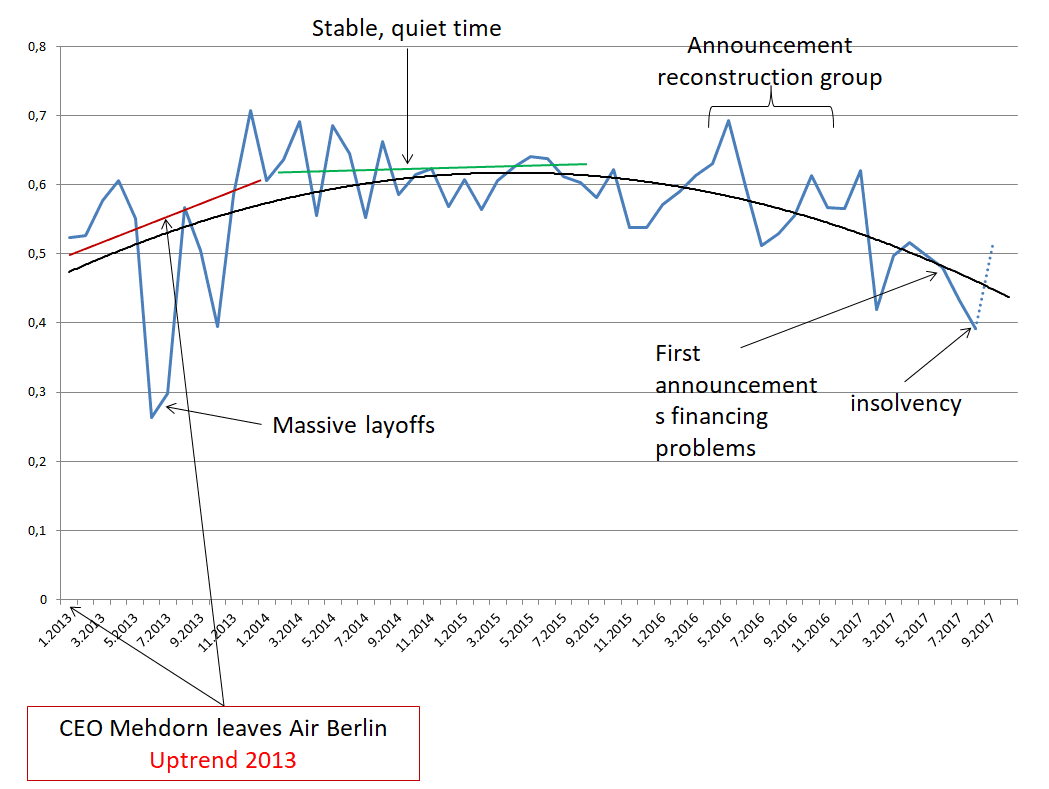
The system can be easily applied to any other product, company, or person. If there is not enough data for a learning set (e. g. parties or persons) the Microsoft API can be used for mood analysis of the individual Tweets.
The analysis of Tweets and posts allows companies to easily monitor public opinions on brand and to identify trends. In addition, some marketing and PR measures aimed at brand building can be evaluated and measured.
){kind=link}