
Data Mining
There is an important distinction related to data mining. First the difference between mining the data to find patterns and build models, and second using the results of data mining. Data Mining results inform the data mining process itself.
The CRISP data mining process
Cross-industry standard process for data mining, known as CRISP-DM, is an open standard process model that describes common approaches used by data mining experts. It is the most widely-used analytics model and breaks the process of data mining into six major process.
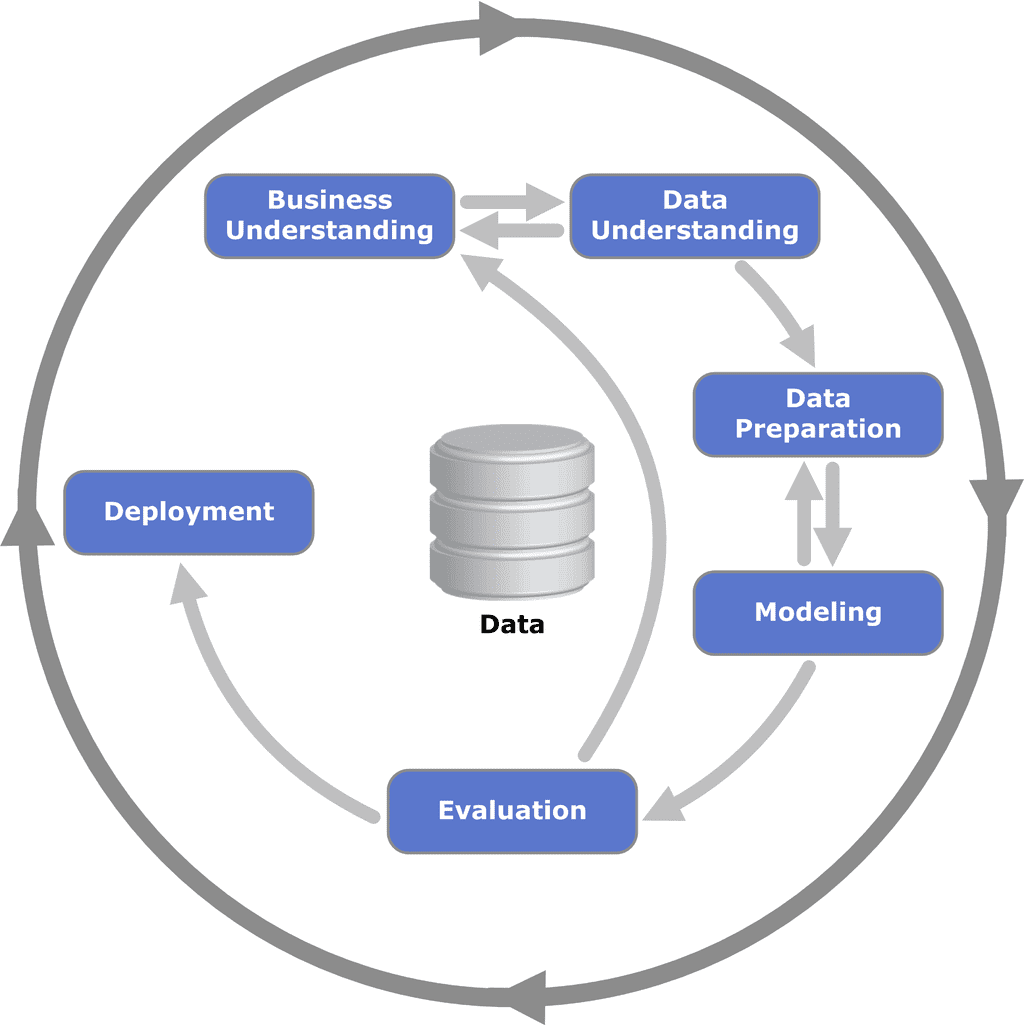
As we can see in the process diagram, the entire process is an exploration of the data through iteration. Let’s discuss this steps now.
Business Understanding
First of all, it is necessary to understand the problem to be solved. This may seem obvious, but recasting the problem and designing a solution is the usual process. As seen in the diagram this is shown by cycles within a cycle. At this stage the analyst’s creativity plays an important role.
As we seen in Part 1 there are powerful tools to solve a particular problem. Therefore, the design team should think carefully about the problem to be solved and about the use scenarios. This itself is one of the most important fundamental principles of data science.
Data Understanding
It is important to understand the strengths and limitation from the available raw material, from which the solution will be built. The data comprise contains different information, which can be historical data, customers data, marketing data or transactional data, from a database. The costs of data is also very important, cause some will be free and others require effort to obtain it. The estimate of the cost and benefits of each data source should therefore be made.
Data Preparation
The next step is data preparation. Usually raw data is not in a format that can be directly used to perform data analysis. Most platforms require data to be in a form different from how the data are provided. In very simple terms, most platforms require data to be in a matrix form with the variables being in different columns and rows representing various observations. Data can be available in a structured, semi-structured, and unstructured form. A significant effort is needed to align semi-structured and unstructured data into a usable form.

One very general and important concern during data preparation is to beware of “leaks”
(Kaufman 2012 – Leaking in data mining: Formulation, detection, and avoidance. ACM Transaction on Knowledge Discovery from Data (TKDD)) If you interested you can read it here:
https://www.researchgate.net/profile/Claudia_Perlich/publication/22…
Modeling
The next step is to put the data to work and build a model. The output of modeling is some sort of model or pattern capturing regularities(trends) in the data. It is important to know some sorts of techniques and algorithms that exist. Models vary in terms of complexity and can range from simple univariate linear regression models to complex machine learning algorithms.
Evaluation
The purpose of the evaluation stage is to assess the results and to gain confidence of valid and reliable data. It also serves to help ensure that the model satisfies the original business goals. The primary goal of data science for business is to support decision making, and solve the business problem. In the evaluation stage even if a model passes, there may be other considerations that make it impractical. The results includes both quantitative and qualitative assessments, so it must be think of the comprehensibility of the model. Finally, a comprehensive evaluation framework is important. For further studies have a look here:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4932655/
Deployment
In the deployment stage the results of data mining are put into real use. Many times, the models have to be corrected and new variables added or removed to enhance the performance. The clearest cases of deployment involve implementing a predictive model in some information system or business process. Additionally, the mining techniques themselves are deployed (for example targeting online advertisements).
Regardless of whether deployment is successful, the process returns to the Business Understanding phase. The process of data mining leads to great insights, so a second iteration can improve the solution. However, there are adjustment all the time, so you can go back from each stage to the prior one.
{kind=link}