
Introduction:
Alex Krizhevsky, Geoffrey Hinton and Ilya Sutskever created a neural network architecture called ‘AlexNet’ and won Image Classification Challenge (ILSVRC) in 2012. They trained their network on 1.2 million high-resolution images into 1000 different classes with 60 million parameters and 650,000 neurons. The training was done on two GPUs with split layer concept because GPUs were a little bit slow at that time.
The original paper is available at ImageNet Classification with Deep Convolutional Neural Networks
Also check: Convolutional Neural Network and LeNet-5
AlexNet Architecture:
The AlexNet architecture consists of five convolutional layers, some of which are followed by maximum pooling layers and then three fully-connected layers and finally a 1000-way softmax classifier.
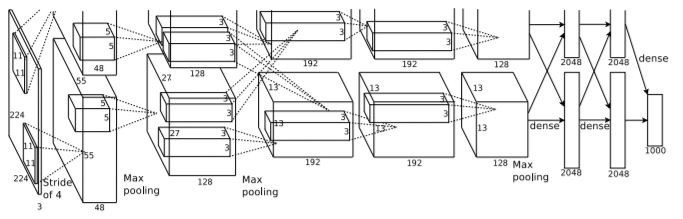
In the original paper, all the layers are divided into two to train them on separate GPUs. Since it is a complex arrangement and difficult to understand, we will implement AlexNet model in one layer concept.
Simplified AlexNet Architecture Video
First Layer:
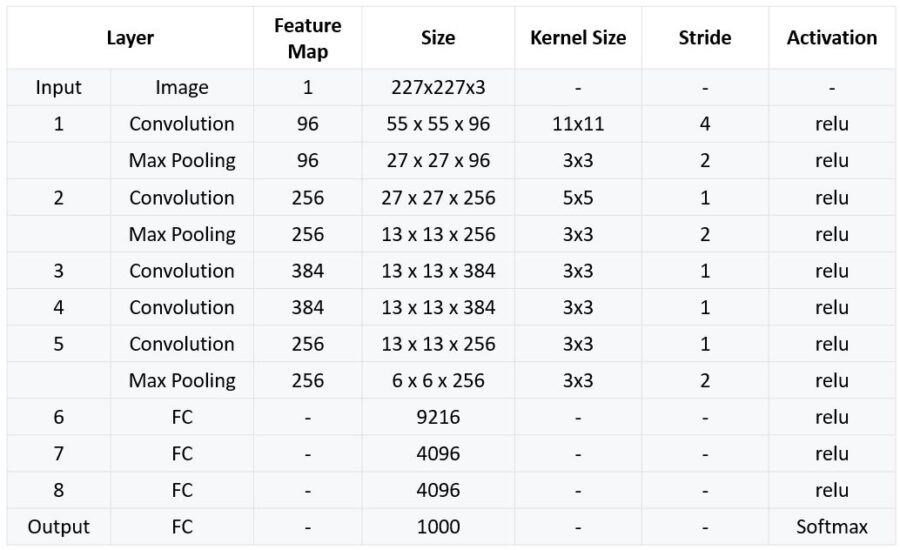
The input for AlexNet is a 227x227x3 RGB image which passes through the first convolutional layer with 96 feature maps or filters having size 11×11 and a stride of 4. The image dimensions changes to 55x55x96.
Then the AlexNet applies maximum pooling layer or sub-sampling layer with a filter size 3×3 and a stride of two. The resulting image dimensions will be reduced to 27x27x96.
Second Layer:
Next, there is a second convolutional layer with 256 feature maps having size 5×5 and a stride of 1.
Then there is again a maximum pooling layer with filter size 3×3 and a stride of 2. This layer is same as the second layer except it has 256 feature maps so the output will be reduced to 13x13x256.
Third, Fourth and Fifth Layers:
The third, fourth and fifth layers are convolutional layers with filter size 3×3 and a stride of one. The first two used 384 feature maps where the third used 256 filters.
The three convolutional layers are followed by a maximum pooling layer with filter size 3×3, a stride of 2 and have 256 feature maps.
Sixth Layer:
The convolutional layer output is flattened through a fully connected layer with 9216 feature maps each of size 1×1.
Seventh and Eighth Layers:
Next is again two fully connected layers with 4096 units.
Output Layer:
Finally, there is a softmax output layer ŷ with 1000 possible values.
Summary of AlexNet Architecture:
{kind=link}