
The future of software development will be model-driven, not code-driven.
Now that my 4th book (“The Economics of Data, Analytics and Digital Transformation”) is in the hands of my publisher, it’s time to get back to work investigating and sharing new learnings. In this blog I’ll take on the subject of Software 2.0. And thanks Jens for the push in this direction!
Imagine trying to distinguish a dog from other animals in a photo coding in if-then statements:
If the animal has four legs (except when it only has 3 legs due to an accident), and if the animal has short fur (except when it is a hair dog or a chihuahua with no fur), and if the animal has medium length ears (except when the dog is a bloodhound), and if the animal has a medium length legs (except when it’s a bull dog), and if…
Well, you get the point.
In fact, it is probably impossible to distinguish a dog from other animals coding in if-then statements.
And that’s where the power of model-based (AI and Deep Learning) programming shows its strength; to tackle programming problems – such as facial recognition, natural language processing, real-time dictation, image recognition – that are nearly impossible to address using traditional rule-based programming (see Figure 1).
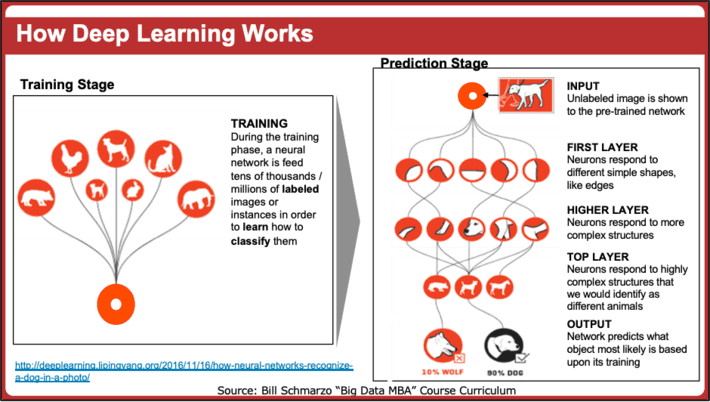
Figure 1: How Deep Learning Works
As discussed in “2020 Challenge: Unlearn to Change Your Frame”, most traditional analytics are rule based; the analytics make decisions guided by a pre-determined set of business or operational rules. However, AI and Deep Learning make decisions based upon the “learning” gleaned from the data. Deep Learning “learns” the characteristics of entities in order to distinguish cats from dogs, tanks from trucks, or healthy cells from cancerous cells (see Figure 2).
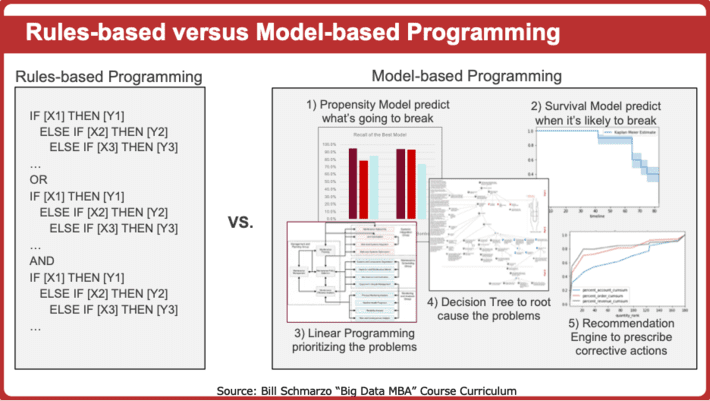
Figure 2: Rules-based versus Learning-based Programing
This learning amplifies when there is a sharing of the learnings across a collection of similar assets – vehicles, trains, airplanes, compressors, turbines, motors, elevators, cranes – so that the learnings of one asset can be aggregated and backpropagated to the cohort of assets.
The Uncertain Future of Programming
A recent announcement from NVIDIA has the AI community abuzz, and software developers worrying about their future. NVIDIA researchers recently used AI to recreate the classic video game Pac-Man. NVIDIA created an AI model using Generative Adversarial Networks (GANs) (called NVIDIA GameGAN) that can generate a fully functional version of Pac-Man without the coding associated with building the underlying game engine. The AI model was able to recreate the game without having to “code” the game’s fundamental rules (see Figure 3).

Figure 3: “How GANs and Adaptive Content Will Change Learning, Entertainment and More”
Using AI and Machine Learning (ML) to create software without the need to code the software is driving the “Software 2.0” phenomena. And it is impressive. An outstanding presentation from Kunle Olukotun titled “Designing Computer Systems for Software 2.0” discussed the potential of Software 2.0 to use machine learning to generate models from data and replace traditional software development (coding) for many applications.
Software 2.0[1]
Due to the stunning growth of Big Data and IOT, Neural Networks now have access to enough detailed, granular data to surpass conventional coded algorithms in the predictive accuracy of complex models in areas such as image recognition, natural language processing, autonomous vehicles, and personalized medicine.
Instead of coding software algorithms in the traditional development manner, you train Neural Network – leveraging backpropagation and stochastic gradient descent – to optimize the neural network nodes’ weights to deliver the desired outputs or outcomes (see Figure 4).
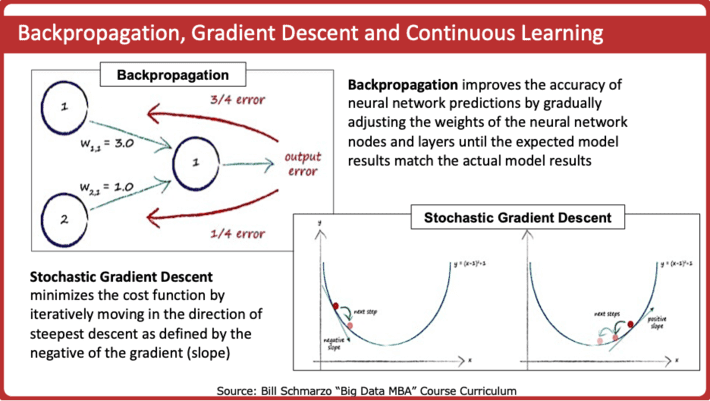
Figure 4: “Neural Networks: Is Meta-learning the New Black?”
With model-driven software development, it is often easier to train a model than to manually code an algorithm, especially for complex applications like Natural Language Processing (NLP) and image recognition. Plus, model-driven software development is often more predictable in term of runtimes and memory usage compared to conventional algorithms
For example, Google’s Jeff Dean reported that 500 lines of TensorFlow code repla…. And while a thousand-fold reduction is huge, what’s more significant is how this code works: rather than half a million lines of static code, the neural network can learn and adapt as biases and prejudices in the data are discovered.
Software 2.0 Challenge: Data Generation
In the article “What machine learning means for software development”, Andrew Karpathy states that neural networks have proven they can perform almost any task for which there is sufficient training data. Training Neural Networks to beat Go or Chess or StarCraft is possible because of the large volume of associated training data. It’s easy to collect training data for Go or Chess as there is over 150 years of data from which to train the models. And training image recognition programs is facilitated by the 14 million labeled images available on ImageNet.
However, there is not always sufficient data to neural network models in all cases. Significant effort must be invested to create and engineer training data, using techniques such as noisy labeling schemes, data augmentation, data engineering, and data reshaping, to power the model-based neural network applications. Welcome to Snorkel.
Snorkel (damn cool name) is a system for programmatically building and managing training datasets without manual labeling. Snorkel can automatically develop, clean and integrate large training datasets using three different programmatic operations (see Figure 5):
- Labeling data through the use of heuristic rules or distant supervision techniques
- Transforming or augmenting the data by rotating or stretching images
- Slicing data into different subsets for monitoring or targeted improvement
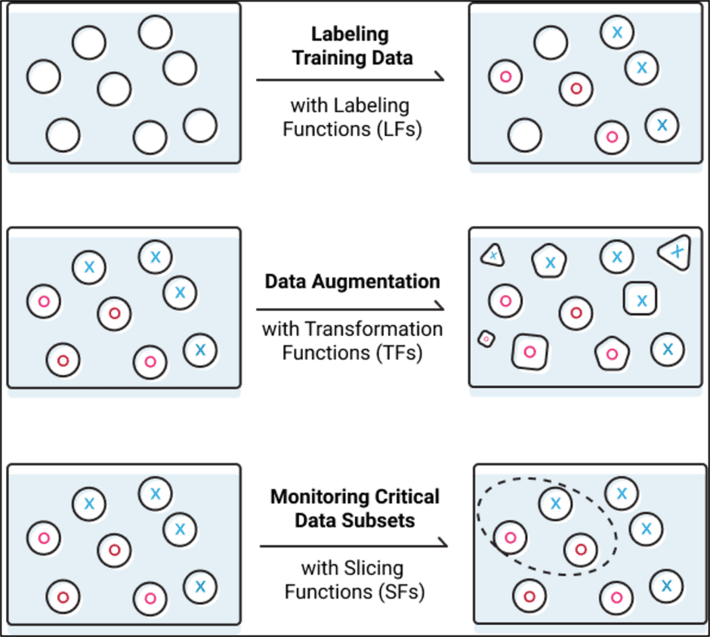
Figure 5: Programmatically Building and Managing Training Data with Snorkel
Snorkel is a powerful tool for data labeling and data synthesis. Labeling data manually is very time-consuming, and Snorkel can address this issue programmatically, and the resulting data can be validated by human beings by looking at some samples of the data.
See “Snorkel Intro Tutorial: Data Augmentation” for more information on its workings.
Software 2.0 Summary
There are certain, complex programming problems – facial recognition, natural language processing, real-time dictation, image recognition, autonomous vehicles, precision medicine – that are nearly impossible to address using traditional rule-based programming. In these cases, it is easier to create AI, Deep Learning and Machine Learning models that can trained (with large data sets) to deliver the right actions versus being coded to deliver the right actions. This is the philosophy of Software 2.0.
Instead of coding software algorithms in the traditional development manner, you train a Neural Network to optimize the neural network nodes’ weights to deliver the desired outputs or outcomes. And model-driven programs have the added advantage of being able to learn and adapt… the neural network can learn and adapt as biases and prejudices in the data are discovered.
However, there is not always sufficient data to neural network models in all cases. In those cases, new tools like Snorkel can help… Snorkel can automatically develop, clean and integrate large training datasets
The future of software development will be model-driven, not code-driven.
Article Sources:
- Machine Learning vs Traditional Programming
- Designing Computer Systems for Software 2.0 (PDF)
- Software Ate the World, Now AI Is Eating Software:
- The road to Software 2.0
{kind=link}