
I often tell my younger coworkers that the most boring way to start a blog post is, “This post is about …” — unless of course you rap it!
Yo!
This post is about generating free text
with a deep learning network
particularly it is aboutBrick X6,
Phey, cabe,
make you feel soom the way (I smoke good!)
I probably make (What?)
More money in six months,
Than what’s in your papa’s safe (I’m serious)
Look like I robbed a bank (Okay Okay)
I set it off like Queen Latifah
‘Cause I’m living single I’m feeling cautious
I ain’t scream when they served a subpoena (Can’t go back to jail)
I heard that he a leader
(Who pood, what to be f*****’ up
The baugerout Black alro Black X6,
Phantom White X6 looks like a panda
Goin’ out like I’m Montana
Hundred killers, hundred hammers Black X6,
Phantom White X6, panda
Pockets swole, Danny
Sellin’ bar, candy
Man I’m the macho like Randy
The choppa go Oscar for Grammy
B**** n**** pull up ya panty
Hope you killas understand me
Hey Panda, Panda Panda,
Panda, Panda, Panda, Panda
I got broads in Atlanta
Twistin’ dope, lean and the Fanta
Credit cards and the scammers
Hittin’ off licks in the bando
You’d think I can rap. I cannot. The rap song above was written by my deep learning rap-trained neural network.
Generating Free Text with LSTM Networks
I do know that recurrent neural networks (RNN)have been successfully experimented in generating free text [i][ii]. The most common neural architecture for free text generation relies on at least onelong short term memory (LSTM)layer.
In a previous post on the KNIME blog, “Once upon a time … by LSTM Network,” K. Melcher[iii]trained an LSTM-based RNN with texts from the Brothers Grimm’s fairy tales downloaded from the Project Gutenberg site.
The network consisted of only three layers: an input layer, an output layer, and, in between, an LSTM layer (Fig. 1).
The network was trained at the character level. That is, sequences of mcharacters were generated from the input texts and fed into the network.
Each character was encoded using the hot-zero encoding; thus, each character was represented by a vector of size n, where nis the size of the character dictionary of the input text corpus.
The full input tensor with size [m, n]was fed into the network. The network was trained to associate the next character at position m+1to the previous mcharacters.
All of this leads to the following network:
- The input layer with nunits would accept [m, n]tensors, where nis the size of the input dictionary and mthe number of past samples (in this case characters) to use for the prediction. We arbitrarily chose m=100, estimating that 100 past characters might be sufficient for the prediction of character number 101. The dictionary size n, of course, depends on the input corpus.
- For the hidden layer, we used 512 LSTM units. A relatively high number of LSTM units is needed to be able to process all those (past mcharacters – next m+1character) associations.
- Finally, the last layer included nsoftmax-activated units, where nis again the dictionary size. Indeed, this layer is supposed to produce the array of probabilities for each one of the characters in the dictionary — therefore, the noutput units, one for each character probability.
Figure 1. The deep learning LSTM-based neural network we used to generate free text. ninput neurons, 512 hidden LSTM units, an output layer of nsoftmax units where nis the dictionary size, in this case the number of characters used in the training set.
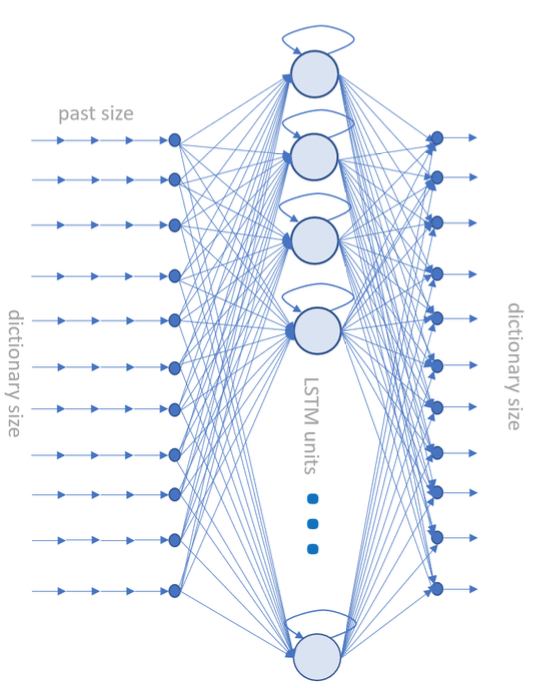
Notice that in order to avoid overfitting, an intermediate dropout layerwas temporarily introduced during training between the LSTM layer and the output dense layer. A dropout layer chooses to remove some random units during each pass of the training phase[iv]. The dropout layer was then removed for deployment.
The KNIME Keras Integration
I am not a Python programmer, and unfortunately, I cannot take the time to learn how to implement and train a deep learning neural network using TensorFlowor even Keras in Python.
However, I am in luck! KNIME Analytics Platformoffers a GUI-based integration of Keras and TensorFlow. Indeed, the KNIME deep learning extension integrates functionalities from Keras libraries, which in turn integrate functionalities from TensorFlow in Python (Fig. 2).
More information on how to install the KNIME Deep Learning –Keras Integration and Python, and on how to connect the two, is available in the KNIME Deep Learning – Keras Integration documentation page.
The advantage of using the Keras integration within KNIME Analytics Platform is the drastic reduction in the amount of code to write. A number of Keras library functions have been wrapped into KNIME nodes, most of them providing a visual dialog window and a few of them allowing for the integration of additional Keras/TensorFlow libraries via Python code.
Figure 2. The deep learning integration in KNIME Analytics Platform 3.7 encapsulates functions from Keras built on top of TensorFlow in Python.
The KNIME Workflow
Another advantage of using KNIME Analytics Platform for my data analytics project is the bonanza of available example workflows, all free to download and scoping a large variety of use cases.
The KNIME workflows used in the blog post “Once upon a time… by LSTM Network” are no exception. These workflows, which train and deploy an LSTM-based recurrent neural network to generate free text from the Grimm’s fairy tales, are available and downloadable for free from the KNIME EXAMPLES serverunder:
04_Analytics/14_Deep_Learning/02_Keras/11_Generate_Fairy_Tales.
Figure 3. The example workflow adopted in the blog post “Once upon a Time … by LSTM Network” as it appears on the KNIME EXAMPLES server under 04_Analytics/14_Deep_Learning/02_Keras/11_Generate_Fairy_Tales.
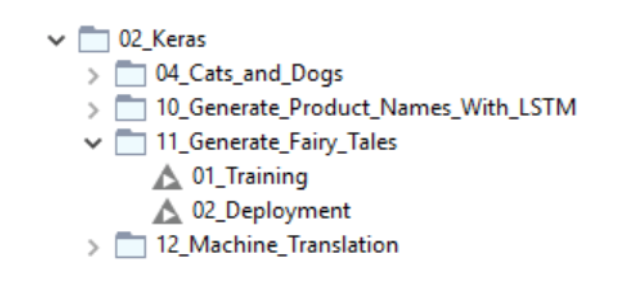
I, of course, tried to save time and downloaded the workflows to adapt them for this particular project of text generation. The folder 11_Generate_Fairy_Tales contains two workflows (Fig. 3):
- 01_Training –trains the LSTM-based neural network
- 02_Deployment –applies the model and generates the free text
I adapted the text preprocessing part and the neural structure to my new corpus of rap songs to obtain the following two workflows.
Figure 4. The training workflow trains a (62 inputs – 512 LSTM – 62 outputs) neural network to predict the next character in the text based on the previous 100 characters. The training set consists of 23 popular rap songs. Thus, the network learns to build words and sentences in a rap song style.
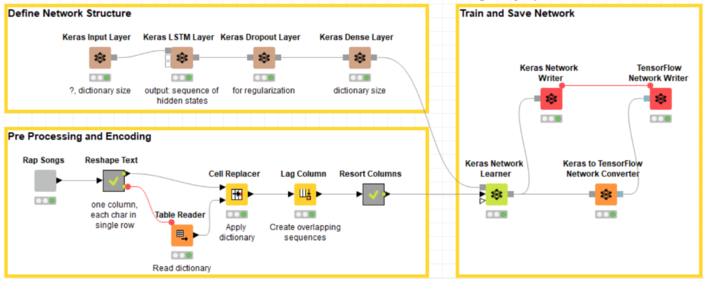
Figure 5. The deployment workflow takes 100 characters as a start and generates the next character in a loop until 1,000 characters are generated, making the full final rap song.
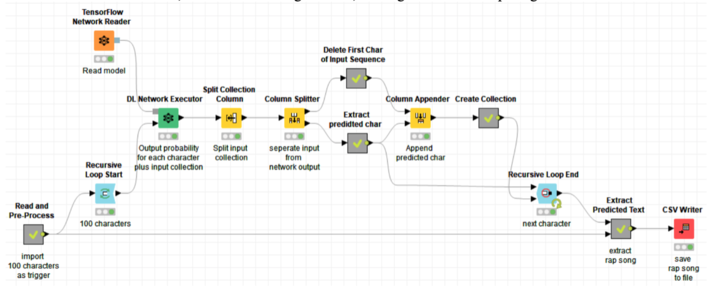
Notice that if the training set is large, this network can take quite a long time to train. It is possible to speed it up by pointing KNIME Analytics Platform to a Keras installation for GPUs.
AI-Generated Rap Songs
I collected texts from 23 popular rap songs (Fig. 6) for a total of 1,907 sentences. Characters were index-encoded and then hot-zero encoded to feed the neural network. A past of 100 characters was used to predict the next character in the sentence. The network was trained on 100 epochs.
Figure 6. The list of 23 rap songs used as training set.
To create a new rap song, we need a sequence of 100 starting characters. The network will then take it from there and create the remaining text in a rap style. Any 100-character sequence would work.
We could start with the first 100 characters of an existing rap song and see how the AI deep learning network would continue it. Rap on rap, however, might not show the big change in free text style.
We could start with the opening line of a fairy tale and observe the transition from sweet and slow to angry and hectic. We took the opening line of “The Golden Bird” from the Grimm’s fairy tale. The result might deserve the title “Snow White Gone Sour.”
A certain king had a beautiful garden,
and in the garden stood a tree
which bore golden apples.
The Pouble trap now my heart
is with whoever I’m st’eppin’
And the motherf*****’ weapon is kept in
A stash box, for the so-called law
Wishin’ Ren was a n***** that they never saw
Lights start flashin’ behind me
But they’re scared of a n****
so they mace me to blind me
But that s*** don’t work, I just laugh
Because it gives em a hint, not to step in my path
Forging as a right
If I had a billion dollars (yeah!)
Yeah, I’d spend as a s***
Mingap notsin’ bodies to this bants a** makin’ shot
But in the Pusso
Beathe from the one that b**** workne
on my tent to the money at vioks
The upbor come from out on tha
why I’m here and I can’t come back home
And guess when I heard that?
When I was back home
Every interview I’m representing you,
making you proud
Reach for the stars so if you fall,
you land on a cloud
Jump in the crowd,
spark your lighters,
wave ‘em around
If you don’t know by now,
I’m talking ‘bout Chi-Town!
I’m coming home again
Do you think about me now and then?
In the rap song above, you can see some overfitting effect due to the too small training set. Indeed, you can recognize pieces from the songs in the training set. However, the result seems quite satisfactory.
Give deep learning a 100 character starting line, and it can rap it!
[i]Ian Goodfellow, Yoshua Bengio and Aaron Courville, “Deep Learning”, The MIT Press, 2016
[ii]J. Brownlee, “Crash Course in Recurrent Neural Networks for Deep Learning,” Machine Learning Mastery, 2016
[iii]K. Melcher, “Once upon a time… by LSTM Network,” KNIME blog, 2018
[iv]A. Budhiraja, “Dropout in (Deep) Machine Learning,” blog post on Medium, 2016
{kind=link}