
I just uploaded a new chapter to my github proto-book “Bayesuvius”. This chapter deals with Reinforcement Learning (RL) done right, i.e., with Bayesian Networks 🙂
My chapter is heavily based on the excellent course notes for CS 285 taught at UC Berkeley by Prof. Sergey Levine. All I did was to translate some of those lectures into B net lingo.
During a recent conversation that I had on LinkedIn with some very smart Machine Learning experts, the experts opined that the fields of RL and B nets did not overlap much. In fact, one of them went so far as to opine that these 2 fields were “incomparable”. My reaction was, well, in the words of Bertie Wooster, “Well, I don’t think I’m going too far, Jeeves, when I say that this just about takes the giddy biscuit!” and “It’s not an expression I often use, Jeeves, but…tuh!”. I silently determined there and then to set them on the straight and narrow, and, after many days of squeezing the old cranial lemon trying to find something juicy to say about the secret love affair between RL and B nets, this chapter is the final outcome.
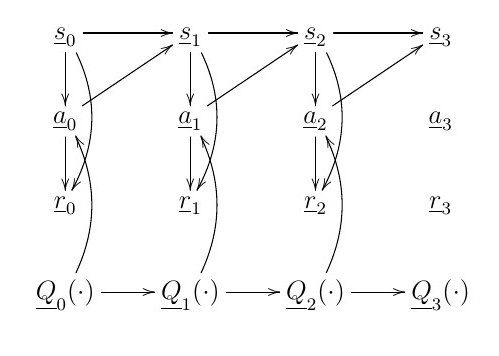
I found that all RL algorithms known to man can be represented as a B net. In my RL chapter, I consider in detail bnets for several famous RL algorithms. Here is the bnet for the simplest RL algorithm, the one often called Q function learning.
{kind=link}