
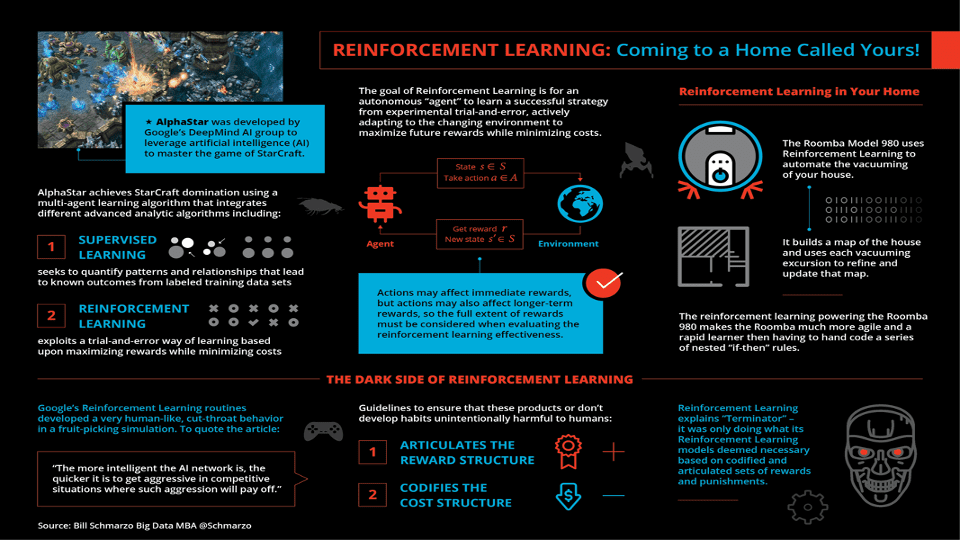
Sometimes, something happens right before your eyes, but it takes time (months, years?) to realize its significance. In February 2019, I wrote a blog titled “Reinforcement Learning: Coming to a Home Called Yours!” that discussed Google DeepMind’s phenomenal accomplishment in creating AlphaStar.
I was a big fan of StarCraft II, a science fiction strategy game that features a battle for galaxy supremacy among three races: the Terrans, Zerg, and Protoss. I always preferred playing as Terran and enjoyed building an impenetrable wall of siege tanks. Yea, baby!!
In competitive gaming, StarCraft II was a formidable challenge. Unlike traditional board games, StarCraft II presents a dynamic environment with partial observability. Players must manage armies, gather resources, and outwit opponents—all in real-time. StarCraft II demands strategic prowess, adaptability, resource management, and lightning-fast decisions.
Google DeepMind launched AlphaStar in January 2019 with the goal of using advanced analytical techniques to beat human players in StarCraft II. By August 2019, AlphaStar had reached the Grandmaster level by defeating some of the best human players in the world. Mission accomplished.
Maybe I missed the significance of the AlphaStar achievement when it first happened because the project did not use the term Artificial Intelligence (AI) to frame its success. Now, in hindsight, AI is what the AlphaStar project was all about.
To learn more about the AlphaStar story, check out Lex Fridman’s podcast #20: “Oriol Vinyals: DeepMind AlphaStar, StarCraft, and Language.” It’s a fantastic podcast chockful of AI application ideas and details that I have listened to at least five times.
AlphaStar: An AI Technology Preview
The AlphaStar project blended cutting-edge analytic techniques to achieve its success, including:
- Neural Networks (including Transformers). Neural networks formed the backbone of AlphaStar’s ability to process and interpret StarCraft’s complex, high-dimensional environment. Transformers, a specific type of neural network, were critical due to their ability to handle data sequences with long-range dependencies. This capability was crucial for understanding the sequential nature of StarCraft II gameplay, where actions and strategies unfold over time. Transformers enabled AlphaStar to analyze the game’s state and the sequence of previous moves, allowing for more sophisticated strategic planning and decision-making.
- Deep Reinforcement Learning (DRL) allowed AlphaStar to engage in extensive self-play, dramatically accelerating its ability to continuously learn and improve with minimal human intervention. The iterative process of self-play, combined with feedback mechanisms inherent in reinforcement learning, meant that AlphaStar could refine its strategies over time, learning from victories and defeats.
- Long Short-Term Memory (LSTM). LSTM networks, a recurrent neural network, were vital to AlphaStar’s ability to remember and utilize information from previous game states. This memory capability allowed the AI to make decisions that considered the current game state and the game’s history up to that point. LSTM helped AlphaStar make short-term tactical decisions considering its long-term strategy. Remembering past outcomes and opponent behaviors enabled the AI to adapt and exploit patterns in the opponent’s strategy.
- Imitation Learning. AlphaStar’s initial training included learning from replays of games played by human professionals. This approach, known as imitation learning, allowed the AI to acquire a baseline level of strategic understanding and game mechanics before engaging in self-improvement through self-play. By analyzing and imitating the strategies used by top human players, AlphaStar could incorporate complex human-like tactics into its strategy pool. This accelerated the AI’s learning process and provided a foundation for developing novel strategies that extended beyond those observed in human play.
The orchestration of these technologies allowed AlphaStar to achieve a level of gameplay proficiency that surpassed human experts, marking a significant milestone in AI research. This is also a precursor to the next big step in AI advancement: Metalearning.
Metalearning
Metalearning allows AI systems to “learn how to learn” in acquiring new knowledge and skills across various tasks and domains with minimal human intervention.
Metalearning involves algorithms that adjust their learning strategy based on performance and task nature. This optimizes learning rates, adjusts model architectures, or selects the best algorithm.
Metalearning isn’t about optimizing a current skill set; it’s about blending the learning across a wide range of skill sets to master an entirely new skill set. It’s mastering the ability to “learn how to learn” (Figure 1).
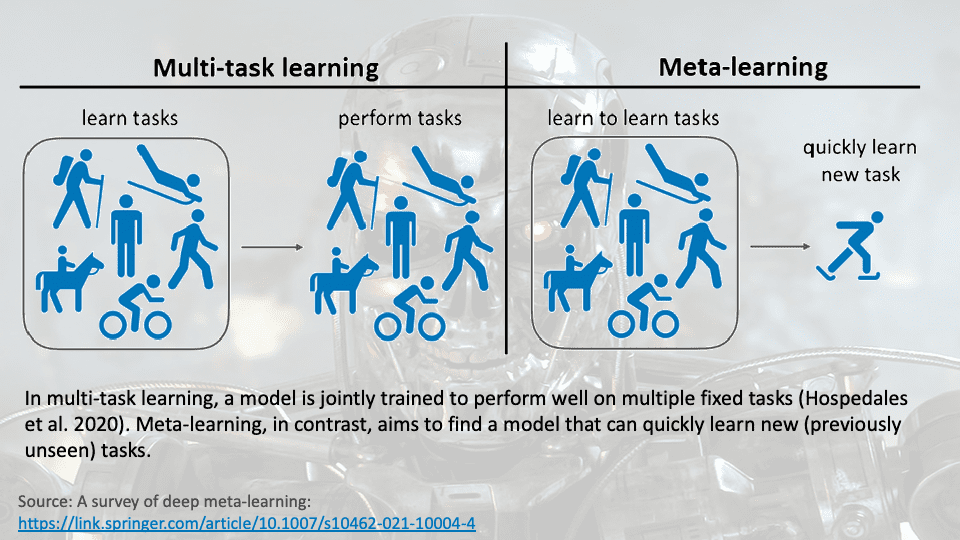
Figure 1: “Source: A survey of deep meta-learning”
The metalearning analogy would be that AlphaStar could more quickly learn and adjust to master another dynamic video game like Warcraft or Halo. It would do this by applying the principles and patterns it learned from StarCraft II, adapting them to the context and requirements of Warcraft or Halo, ultimately accelerating its path to mastery. The underlying metalearning framework would enable it to understand and adapt to the new game’s unique mechanics and strategies more rapidly than building an AI agent from scratch.
The future of Metalearning is bright, including:
- Enhanced Learning Algorithms: Ongoing research in metalearning aims to develop algorithms to learn more effectively across various tasks, reducing reliance on large datasets and extensive training periods.
- Application in Complex Environments: As metalearning techniques become more sophisticated, their application in complex, dynamic environments such as autonomous driving, healthcare, manufacturing, and personalized education is expected to increase, providing systems that can adapt and learn from minimal interaction or guidance.
- Ethical and Safe Deployment: As AI systems increase their adaptability and autonomy through metalearning, the importance of ensuring they are developed and deployed ethically and safely grows. This includes considerations for transparency, accountability, and minimizing unintended consequences and confirmation bias.
What If…Metalearning Meets TLADS
This research into metalearning got me thinking: can I leverage metalearning concepts and techniques to enhance my “Thinking Like a Data Scientist” (TLADS) methodology to create a blended human and AI culture of continuous learning and adapting?
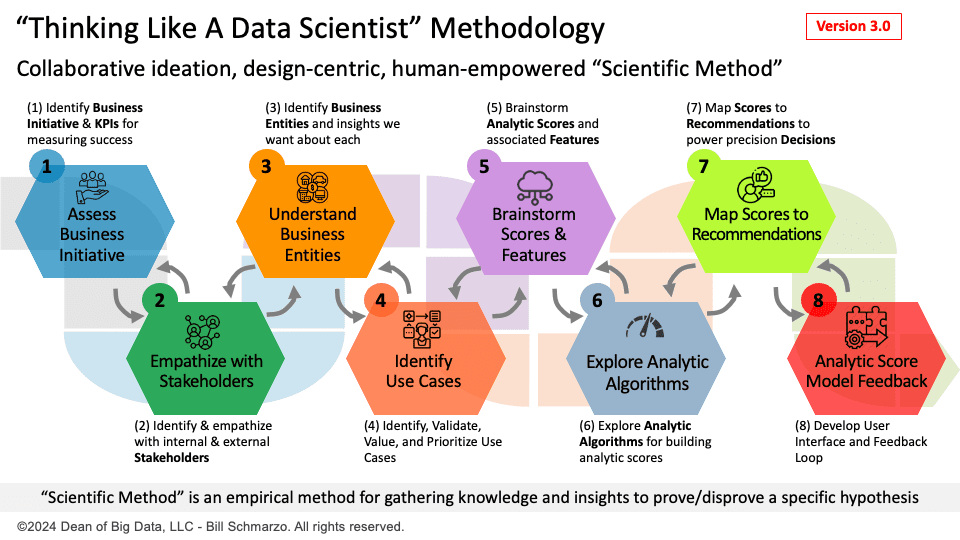
Integrating metalearning with the TLADS methodology offers capabilities that can supercharge an organization’s data science and AI approaches, including:
- Adaptive KPI Selection: Metalearning would facilitate the dynamic selection and adjustment of Key Performance Indicators (KPIs) in response to changing business environments. Integrating this with the first step of the TLADS methodology—Assess Business Initiative —means organizations could automatically update their success metrics to align with evolving strategic objectives, ensuring that data science initiatives remain relevant to the organization.
- Improved Stakeholder Alignment: By incorporating metalearning into stakeholder engagement—Step 2: Empathize with Stakeholders—organizations could systematically capture and analyze stakeholder usage and feedback patterns, enhancing the effectiveness of future interactions. This leads to a more empathetic approach to problem-solving, with data science initiatives becoming more attuned to internal and external stakeholders’ changing needs.
- Proactive Use Case Identification: Metalearning can predict the potential success of use cases by analyzing historical outcomes, thus guiding data scientists to prioritize projects with the highest business impact. By embedding metalearning into TLADS Step 4, “Identify Use Cases,” organizations can better allocate their precious data and analytic resources to high-value/high-feasibility business and operational initiatives.
- Optimized Algorithm Selection: With metalearning, algorithms can be chosen based on their theoretical suitability and proven practical performance across similar tasks. This means that when exploring analytic scores analytic algorithms—Step 5: “Brainstorm Analytic Scores” and Step 6: “Explore Analytic Algorithms”—organizations can lean on metalearning to guide them towards analytic scores and enabling analytic algorithms previously shown to be effective, accelerating time-to-value, reducing implementation risks, and improving outcomes.
- Continuous Model Improvement: Metalearning introduces a robust framework for continuous learning, enabling AI models to evolve and adapt even post-deployment. This would supercharge TLADS Step 8: “Analytic Model Feedback” and create the feedback loop that ensures the analytic models constantly improve and adapt, reduce the maintenance burden, and improve long-term model accuracy and relevance.
The fusion of metalearning with the TLADS methodology would equip organizations with a strategic advantage: the ability to continuously learn and adapt in an ever-changing operational environment with minimal human intervention. It signifies a shift from static, one-off data science projects to developing dynamic, evolving analytic assets that grow in intelligence and value over time.
Summary
AlphaStar’s triumph in AI marked a significant advance, laying the groundwork for metalearning. By integrating neural networks with transformers, deep reinforcement learning, and LSTM networks, AlphaStar showed the adaptability and efficiency needed for continuous AI evolution, and reaching the goal of AI models that can continuously learn and adapt, regardless of the domain, with minimal human intervention or guidance.