
This article is more about building better LLM and GPT-like applications, than search. Yet most people use GPT as a substitute for search. Indeed, OpenAI replaced search by prompt (the same thing, in the end) probably because the founders thought that there has to be something better. They could not find anything and created they own solution. So did I (see XLLM here), as well as many others. Yet, millions of websites are missing opportunities because they offer poor search to their customers.
In particular, XLLM is an example of how you can get much better results than those from native search on the original website. Local search boxes probably still rely on 20-year-old technology. They can’t compete with a third party smartly extracting information from your website to return better results to the user. While Google offered good enterprise search that you could use to power your search box ($2,000/year for our website), it discontinued the service. Now many websites have relatively poor search capabilities. And even GPT is far from perfect. There is demand here, waiting for a startup the seize the opportunity (I am working on it).
In this article, I discuss a few key strategies that can dramatically improve all of this. Be it search or GPT. They are easy to implement, without costly neural networks requiring a lot of training. Indeed, without any algorithmic training at all!
1. Customized Embeddings
Break down your information database (what you crawled for instance) in 20 or so top categories. Have a separate embedding table for each category. In my case, it’s not just embeddings but other tables such as local taxonomies. Have a separate one for each top category, allow for overlap. In order words, avoid silos: they will dilute the quality of your output. Twenty embedding tables, each with 50k keywords, is better than a single one with 1 million keywords.
2. High-quality taxonomy
Creating or relying on a good taxonomy helps you create better embeddings and better results. The words found in category and sub-category titles should be added to the embeddings, with a higher weight. Category titles are cleaner than raw text found on web pages. In case of parsing books, sections and subsection titles could carry a higher weight than raw text. When I crawled Wolfram, I retrieve the full taxonomy with 5000+ entries, all man-made by experts. It is one of the main contributors to the output quality.
3. Self-tuning
All GPT-like apps have several parameters, transparent to the user. For instance, the user can’t choose which thresholds to apply to the embeddings. Allow the user to set all the parameters to her liking. This way, you can collect the most popular choices for your parameters, based on user feedback. Of course, this is done automatically on a permanent basis. In the end, you come up with optimum parameters. Trained in real-time by human beings! (this is what I meant by no algorithmic training; it is replaced by humans)
Even better: offer the user the ability to keep his favorite, self-customized set of parameter values. In the end, there is no one-size-fits-all evaluation metric. My XLLM is terrible for the novice looking for basic definitions, while GPT is a lot better. Conversely, for professional users looking for research results or serious references, the opposite is true.
4. Offer two prompt boxes
One for the standard query. And one where the user can suggest a category (or two) of his own. You can offer a selection of 10 or 20 pre-selected categories. But you might as well let the user enter a category himself, and process that information as a standard text string. Then match it to existing categories in your system. And then, process the user query or prompt, and match it to the right category to return the most relevant results. Remember, each top category has its own embeddings! You want to use the correct embedding table(s) before returning results.
5. Multi-agent system
This is becoming a hot topic! Some say 2024 will be the year of the customized GPT. A multi-agent system is simply a top layer in your system, controlling all the top categories and embedding tables. In short, it glues the various customized embeddings together, allowing them to “communicate” with each other. In other words, it controls the cross-interactions. It is similar to multimodal (blending images and text) but for text only (blending multiple top categories).
6. Weighted sources
Your app will blend multiple sources together. Say one of your top categories is statistical science, and it has one specialized embedding table. The content may consist of crawled books and crawled sub-categories both in Wolfram and Wikipedia. Not all sources carry the same weight. You want a well-balanced embedding table. If (say) Wikipedia has more stuff, typically of lower quality, you want to weight that source appropriately.
7. Find structured data
The Internet and most websites are considerably more structured than most people think. You just have to find where the structure is hiding. In the case of Wolfram, it comes with a nice taxonomy, among other structures. Wikipedia has its own too. If you crawl books, look for indexes or glossaries and match index terms back to entries in the text. Indexes also have sub-entries and cross-links between entries, that you can leverage.
Even better: each entry (index term) is in some sections or subsections, in addition to being in sentences. Use the table of content and the sectioning as a pseudo-taxonomy. Associate section keywords with index terms found in it. Et voila! Now you have strong keyword associations, in addition to the loose associations when focusing on raw (unstructured) text only.
Example
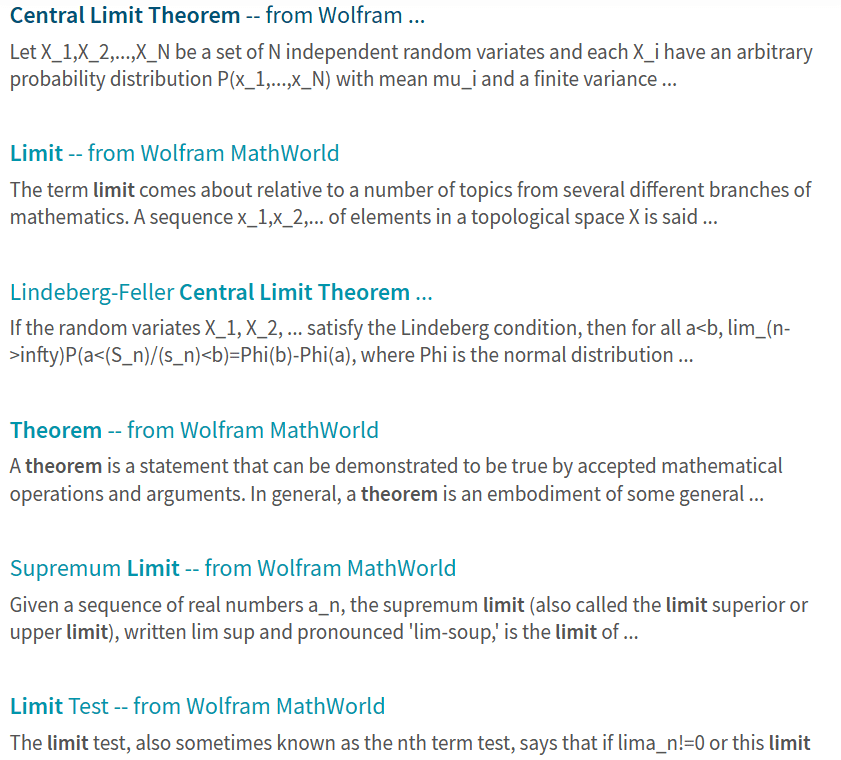
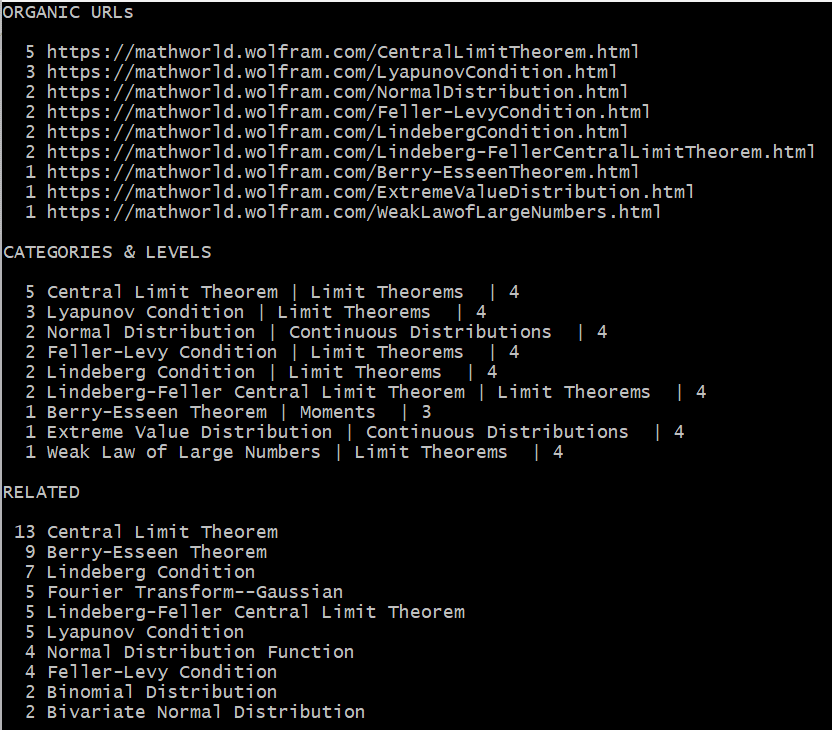
Here I compare the search results from 3 apps, for the query “central limit theorem”. I won’t comment and will let you judge by yourself. In each case, this is the output from a single query. You are welcome to test these tools yourself (contact me for XLLM). I did not include Google search: it returns a bunch of rudimentary articles on the topic.
What is very interesting is the comparison between XLLM and Wolfram. Both are designed to return highly relevant, specialized results related to mathematical or statistical questions. For Wolfram, I use its internal search box. As for XLLM, it is based on my crawl of the entire Wolfram website. This illustrates how a third party can provide much better results (at least for my needs) compared to the tool sitting on the website itself! If you do a Google search and ask to return results only from Wolfram, you get pretty much the same results and poor quality as from the internal Wolfram search box.

Author

Vincent Granville is a pioneering GenAI scientist and machine learning expert, co-founder of Data Science Central (acquired by a publicly traded company in 2020), Chief AI Scientist at MLTechniques.com and GenAItechLab.com, former VC-funded executive, author and patent owner — one related to LLM. Vincent’s past corporate experience includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET. Follow Vincent on LinkedIn.
{kind=link}