

n this post, we discuss the future of autonomous systems and AI.
Let’s consider the case of autonomous racing cars. Berkeley Autonomous Race Car (BARC), Amazon Deep Racer, and others are examples of autonomous racing cars which can be raced effectively without human input.\
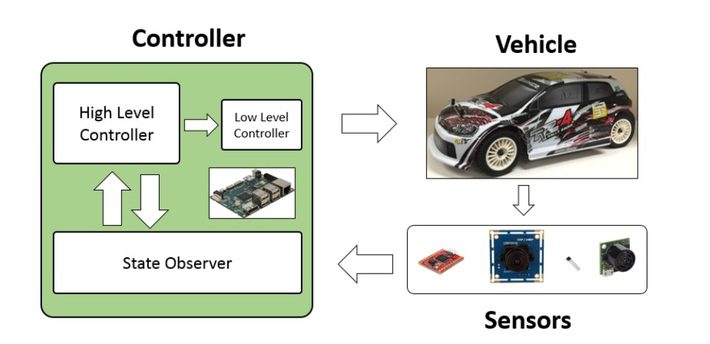
The control systems for these cars are enhanced by AI and neural networks.
Certain parts of the automation, such as guiding wheels, can be managed by traditional techniques like Model Predictive Control (MPC).
However, these traditional techniques are not able to manage the process of driving like a human driver.
To achieve complete and effective autonomy, we need AI techniques.
Expanding from this ‘toy example’ of autonomous racing cars, we can consider the same situation more broadly for control systems.
Control systems can be used to optimize complex processes (such as in supply chain or manufacturing).
However, like the autonomous cars we discussed before, these situations cannot rely on MPC alone.
To achieve autonomous behavior in complex industrial processes, we have to combine MPC techniques with Deep Reinforcement Learning (DRL).
Evolution of control loop systems
To understand this scenario, we have to consider the evolution of control systems.
We can think of autonomous behavior as a control loop problem.
In the simplest case, we have open-loop systems with no feedback mechanism. In this case, we rely only on the mathematical model underlying the process to be accurate under all conditions.
However, this approach has limitations because the operational conditions of the system could change, and we need the system to evolve with it.
Hence, we have feedback control systems.
Feedback control systems suggest the following control action based on the dynamic conditions.
Feedback control systems like PID controllers use constant mathematical gains to move toward the objective while calculating the following action dynamically. This control paradigm is already mature in heavy engineering such as chemical engineering.
Expanding from PID controllers, Model Predictive Control, or MPC controls processes autonomously under a specific set of constraints based on a predictive mechanism.
MPCs use a constraint optimizer to predict the action in advance and an accurate system model for understanding the environment. MPC models work when accurate models of the world exist and when the problem can be framed in terms of a linear equation. However, nonlinear MPC systems that can handle complex, chaotic situations are not so common. Also, MPC needs very accurate models, and building such models can be costly and time-consuming.
Deep Reinforcement Learning (DRL) is based on neural networks and learning by trial and error. DRLs can potentially add learning, strategy, advanced control, and autonomy. DRLs learn by trial and error. Despite their advantages, DRLs also have some disadvantages. DRLs are not easy to train, and they can be trained with less cost when the situation can be simulated virtually. In other words, it’s not feasible to learn by iterations/trial and error in the physical world. Hence, a potential solution is to complement MPCs with DRLs
To further evolve control loop systems with MPCs and DRLs, we need to deploy machine teaching. Project Bonsai is an example of a system using machine teaching. Machine teaching introduces human (expert)expertise into the feedback loop. For example, in the process of making cement, MPC cannot make all decisions in real time. So, human experts could provide feedback via the DRL modules, when then become set points for the MPC to execute safely within defined parameters.
Conclusion
I see the approach of machine teaching in a broader context of the limitations of pure deep learning / neural networks. There are many cases where the traditional neural network approach will not work because there are many complex cases, the risks are high, or the situation cannot be easily simulated. I expect we will see more of this approach in the future.
Sources
Production-ready autonomous systems
Image source Berkeley Autonomous Race Car (BARC),
{kind=link}