
Probably like most people, I tend to recognize data as a stream of values. Notice that I use the term values rather than numbers although in practice I guess that values are usually numerical. A data-logger gathering one type of data would result in data all of a particular type. Perhaps the concept of “big data” surrounds this preconception of data of type except that there are much larger amounts. Consider an element of value in symbolic terms, which I present below: there is an index such as date and of course a value such as the closing stock market price for that date. Other types of values include status or condition (e.g. premises closed); service provider (e.g. John Smith); market (e.g. Toronto); and constraint (e.g. holiday service). The index doesn’t have to be the date specifically. For instance, it can be the time deployed or work requisition number. A data-processing environment might retain data in this straightforward manner, which can be depicted as a two-column table: the first column being the index, the second for the associated values. If the data contained in a larger body share the same index, the table can have many columns without any loss of information. At least this is how I conceptualize the situation.
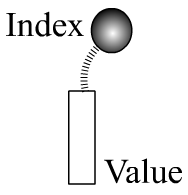
Invoking a less attractive object from such a pristine primitive is like writing a program in Java instead of C. C is a beautiful language in appearance. It is like the shark that evolution doesn’t bother changing because it is already so perfect. Java is also fairly attractive but just not at the same level or way. I think that people responsible for handling lots of data are sometimes compelled by the enchantment of simplicity. It is difficult to turn away from such a pretty simple thing. Er, well, it is usually much easier to do calculations making use of data that is presented as a primitive. The methodologies in place have been around a long time. Don’t laugh, but something that often works well with a primitive data stream is addition. I know this might seem like a peculiar observation. Once I start discussing data in an objectified form, something as simple as addition starts to seem kind of complicated.
In terms of objectified forms for handling data, of course there is no single type. I will share a structure that I use. The next image retains the original primitive, but there are (potentially) many other linkages. When the value of a primitive is numerical, it can be handled mathematically. But the fact that a value is numerical doesn’t mean that it is inherently so, only that we have chosen to impose a nature or signification for mathematical purposes. For example, if I choose to express “3 cars” as “HHJYKULM,” clearly HHJYKULM is not something that can be added to anything else since it is not numerical for mathematical purposes. However, HHJYKULM remains to symbolize 3 cars. It is important therefore to distinguish the mathematical significance of “3 cars” from its underlying symbolic potential, some aspects of which might necessarily be mathematical. In any event, instead of referring to values, I refer to these elements as symbols. A symbol can be “red hat,” “loud baby,” “tasty meal,” and “$14.95.”
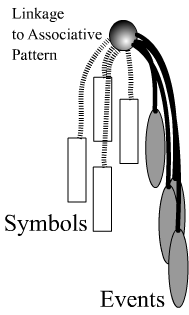
Now, those that have collected a lot of data in its primitive form without any “events” will find that they possess a great deal of essentially worthless data. It isn’t entirely worthless. It might be possible using primitives and non-sophisticated statistics (the sort that I use) to recognize or confirm the existence of problems: e.g. “Your company has a serious revenue problem!” However, the primitives provide little guidance in terms of problem-resolution usually due to the absence of structural data. Those running the company might say, “Well, we know. What should we do about it?” The utter lack of fidelity in the primitive becomes apparent. Events often contain structural details. The absence of events linked to the symbols makes it difficult for an analyst to offer structural developments to the organization that are connected to the data. The fascinating pathology surrounding the absence of structural data is something that I covered a bit in my previous blog, “Legitimizing Corporate Pornography.” When the underlying reality of the market is cut off from the organization – from its data in an actual structural sense – there remains a need to guide the company. The void is filled with socially-constructed beliefs and perceptions.

Processing a data stream of primitives is literally a “straightforward” situation as shown on the top image. Sometimes the index exists simply for sorting purposes so the values can be processed in a particular order. The index serves a similar purpose for objects. But when data is spread out over many thousands of files and folders rather than on a single table, it might not be possible to process data “in order.” The index can therefore be used as a frontline filter to determine whether the rest of the objective is relevant. What I do is create a short program to compile a manifest of relevant objects to process based on the index. The manifest would contain the last known paths to objects. Before actually including the elements of objects at processing, the index can be checked to ensure it remains relevant.
Symbols can be interpreted in a number of ways. I usually think of them as “conditional categories” to determine whether the events should be included – the same way the index serves as a frontline conditional. More philosophically, one might think of symbols as the “passport” identifying the events. For those more statically inclined, symbols might be regarded as the demographics of the events. When I compile narrative code, I treat symbols in two distinct ways: 1) to make the circumstances of the narrative conditional (e.g. death investigated as a serial-killing); 2) to make the features of the narrative conditional (e.g. multiple stabbing). So great is the power of computers these days, I sometimes handle events themselves in a conditional manner: e.g. event is “involvement of a red sedan” – find homicide cases and circumstances attached to this event.
A fine question to ask is, “What makes something a symbol or an event?” This is a deep question that I have chosen to address using an analogy: the symbols are the pieces of the puzzle; but the events are how the pieces fit together. Recall how I said that the events are “structural.” So in a narrative, if I know how things come together but not what, it would be illogical to approach the problem using symbols. I would investigate the events in order to obtain the symbols. Another way to regard the interaction between symbols and events is from the perspective of a medical treatment: symbols are the treatments or treatment outcomes; events are the elements of treatment such as the drugs administered. Having a treatment is quite different from having the data on its quotidian administration except I suppose under laboratory or tightly controlled hospital conditions. Other interpretations for symbols (left) and events (right) include: effect and cause; consequence and experience; sales and circumstances; return and investment.
Something that I do with symbols – which helps me to determine what to use as a symbol – is to create thematic arrays: e.g. terrible, bad, fair, good, excellent. Such a spectrum of categories results in a distribution of events, which can then be analyzed in a statistical manner. I would tend to use statistics on such an abstraction; but I would allow “event detection” to be internally defined by the data itself. So any loss in fidelity occurs from phenomena. Normally when I gather data for statistical analysis, I would filter phenomena based on criteria; so there would be an utter lack of fidelity. For example, if I walk into a room of dogs, I can distribute the dogs based on criteria for “big dog” and “small dog.” Thus the distribution is externally defined; and not much else can be extracted from the data once it is defined that is free of this deep confinement. I can instead have a chat with each dog owner with their dog and compile many thousands of strands of reality from these interviews. A concept that is a bit unusual is “mass data assignment” where I simply dump large amounts of data into symbolic vats; this process is more aligned with today’s computational capabilities.
The use of objects is more taxing on a computer system given that objects literally contain more data than primitives. So if somebody has a “big data” system based on primitives, it will have to be much bigger if objects are used. It also takes much more effort to handle objects. There is a need for both speed and power. So if the idea is to sell new processing system to an organization, maintaining and legitimizing the primitive regime is a bit like marketing suicide. Of course, it depends on the organization acquiring the system. An organization currently making use of spreadsheets (bodies of primitives) – having no intention of changing its methods – probably doesn’t “need” to upgrade. I personally almost always handle data in an open object form when I am free to do so. This means that I have to be able to run specialized software to handle the objects. I admit the situation remains less than ideal since I still tend to use primitives to earn a living. So this is Batman writing about having a fancy utility belt while nonetheless wearing suspenders to keep his pants up.
{kind=link}