
Introduction:
Machine Learning is a vast area of Computer Science that is concerned with designing algorithms which form good models of the world around us (the data coming from the world around us).
Within Machine Learning many tasks are – or can be reformulated as – classification tasks.
In classification tasks we are trying to produce a model which can give the correlation between the input data  and the class
and the class  each input belongs to. This model is formed with the feature-values of the input-data. For example, the dataset contains datapoints belonging to the classes Apples, Pears and Oranges and based on the features of the datapoints (weight, color, size etc) we are trying to predict the class.
each input belongs to. This model is formed with the feature-values of the input-data. For example, the dataset contains datapoints belonging to the classes Apples, Pears and Oranges and based on the features of the datapoints (weight, color, size etc) we are trying to predict the class.
We need some amount of training data to train the Classifier, i.e. form a correct model of the data. We can then use the trained Classifier to classify new data. If the training dataset chosen correctly, the Classifier should predict the class probabilities of the new data with a similar accuracy (as it does for the training examples).
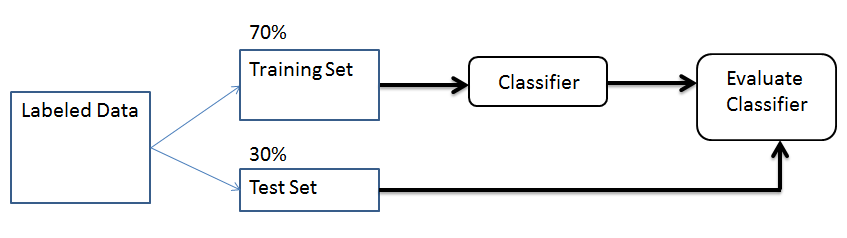
After construction, such a Classifier could for example tell us that document containing the words “Bose-Einstein condensate” should be categorized as a Physics article, while documents containing the words “Arbitrage” and “Hedging” should be categorized as a Finance article.
Another Classifier (whose dataset is illustrated below) could tell whether or not a person makes more than 50K, based on features such as Age, Education, Marital Status, Occupation etc.
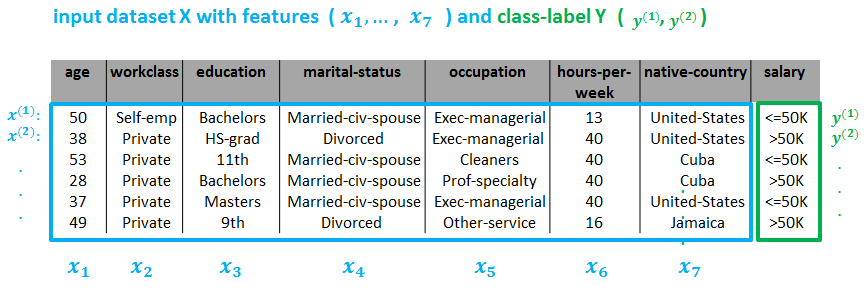
As we can see, there is a input dataset which corresponds to a ‘output’  . The dataset contains
. The dataset contains  input examples
input examples , and each input example has
, and each input example has  feature values
feature values  (here
(here  ).
).
There are three popular Classifiers within Machine Learning, which use three different mathematical approaches to classify data;
- Naive Bayes, which uses a statistical (Bayesian) approach,
- Logistic Regression, which uses a functional approach and
- Support Vector Machines, which uses a geometrical approach.
Previously we have already looked at Logistic Regression. Here we will see the theory behind the Naive Bayes Classifier together with its implementation in Python.
For the rest of the post, click here.