
There are many who believe all the true transformational opportunities for quantum improvements in business are to found only by exploring the unknown-unknowns through big-data analytics.
So what exactly are the unknown-unknowns and how do they change as the organizations mature? For organizations embarking on analytics-journey, what would be a bigger priority? Known-unknowns or unknown-unknowns? Here is my attempt at answering these questions:

Donald Rumsfeld’s famous comment about unknown-unknowns in a news briefing of 2002 has become the mantra of the Big-data world. There are indeed many who believe the future of data-science is in unknown-unknowns, and all the true transformational opportunities for quantum improvements in business are to found only by leveraging big-data analytics into exploring the unknown-unknowns.
I felt compelled to write about the unknown-unknowns when I saw a fair-few of those who went through my earlier article (published on Data-Science Central) have complimented me on coming out with a valuable methodology for perfecting the known’s.
As explained in my earlier article, any organization setting-out to become data-driven and embarking on analytics journey needs to prioritize its investments by targeting opportunities with highest return-on-investment first; Create a priority-roadmap for analytics investments based on relative business value and complexity score. Now the moot point is where exactly the organization is likely to find highest ROI – Is it in Known-Known’s, or in Unknown-unknowns?
I remember reading a number of articles on this very subject when I was tasked with creating a roadmap & business case for analytics in one of my earlier assignments and several more subsequently. There was one published on BBC, by Dr. Mike Lynch – CEO and founder of Autonomy (HP) – where he suggests there is an information goldmine in unknown-unknowns; He goes on “For CEOs, using technology to spot the unknown-unknowns during this time of economic uncertainty will be regarded as a superpower, helping them to make better business decisions and ultimately beat the competition”
One particular incident is still very fresh in my memory. I was having one of those Friday evening drinks with a set of consultants (from a well-known consulting company) and after downing a third, one of the partners politely inquired as to the progress I made on my little analytics roadmap assignment. I truthfully confessed I was not making much headway as “I still do not have clarity on which specific decisions need to be supported with what kind of analytics”. He dis not raise from his seat, but it felt as if he did, as he looked-down at me as a ninety-year-old would at a new-born.

“You are doing it all wrong …”, he did not exactly call me a novice, but it felt as if he did.
“My dear friend, you are barking up the wrong tree” he was all mysterious as he declared “analytics is all about unknown-unknowns…there is a goldmine there”.
No one can possibly deny the value of Big-data analytics when it comes to sifting the known unknowns and unknown unknowns in areas such as fraud detection, Identity theft etc. from huge number of credit card transactions, spotting patterns or mavericks from very large data-sets such as Social Media data. There is a SAS article which describes how Big-data analytics can help tackling the growing terror threats – known unknowns and unknown unknowns that Donald Rumsfeld mentioned in his speech in 2002.
But when it comes to Enterprise Analytics, I believe the unknown-unknowns are different for different Organizations, and are determined by the maturity of the Organization. One of the recent articles I found closer to my thinking was by Anita Andrews of RJ Metrics. She makes a convincing argument as to why organizations aspiring to be great should explore the Unknown Unknowns.
So what exactly are unknown unknowns and how do they change as the Organizations mature? For organizations embarking on analytics-journey, what would be a bigger priority? Known-unknowns or unknown-unknowns?
Here is my attempt answering this question…
Unknown unknowns:
Donald Rumsfeld is supposed to have coined this phrase for the first-time in response to a question in a news briefing in 2002. I also came across an interview published in ensighten mentioning astrophysicist and data-scientist Dr. Kirk Borne had been using the phrase a few years before it percolated down to Donald Rumsfeld. In reality, the concept of Unknown unknown’s was first introduced by psychologists Joseph Luft and Harrington Ingham in 1955, when they created Johari window as a technique to help people understand relationship between themselves and others.
Whatever may be the actual origin, in theory, there is supposed to be an untold amount of treasure in terms of data & actionable insights just waiting to be unearthed in Unknown-unknowns. 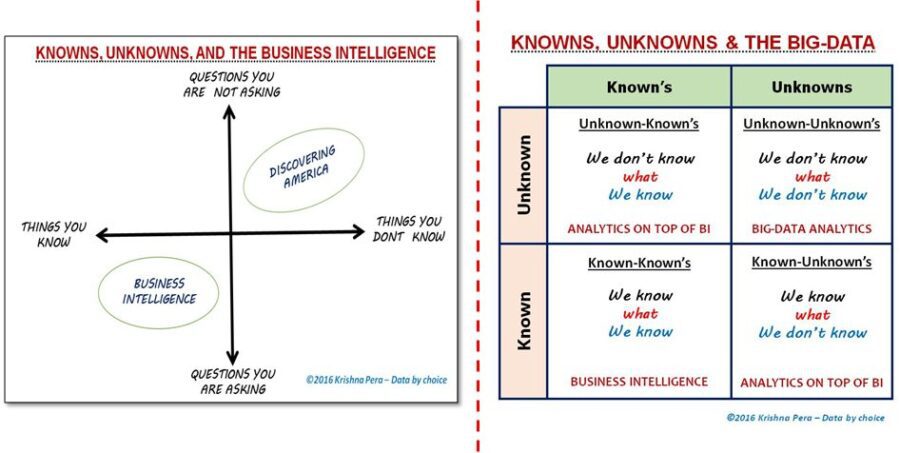
The picture above explains the concept. Theoretically, one could find as much value in unknown-unknowns as Columbus did when he accidentally discovered America. (Though one could argue Columbus was actually asking-a-question, albeit a wrong one, when he set-sail to discover a sea-route to India.)

Big-data as a concept has tremendous value where we deal with huge population of statistical data, and where it becomes nearly impossible to take out a representative sample, no matter what the sampling technique is. The real-life examples include Pharmacogenomic data, Demographic data etc…
However any organization embarking on analytics journey needs to prioritize its analytics investments… target highest relative value first. So here are a few questions that need to be answered….
- What should be a bigger priority? Known Known’s or Unknown Unknowns?
- Does it make sense to explore unknown-unknowns, even before exhausting all the actionable insights from the data that is captured-available within the organization i.e., Known-Known’s?
- What are the odds of finding highly valuable insights from Unknown-unknown’s?
From my experience, a good many organizations are yet to get their Business Intelligence strategy right. Most CIO’s would tell you majority of the BI reports they generate are hardly ever used by their Business Users.
While a good part of the problem lies in a poorly executed Data-strategy; we have also noticed way too often the Business Intelligence initiatives get conceptualized far-far away from business reality and requirements, by IT companies which have no understanding of the domain, and as a result poorly address the business problems, and not surprisingly have very poor acceptability among-st the Business Users.
Unknown unknown’s: Johari Window for an Organization.
Last time I created my own Johari window as a part of T-group sessions was close to 30 years back, when I was a fresh Management Trainee working for an Aerospace company…Those of you who have gone through the exercise would remember the way to self discovery would be tell more about yourself (be transparent) and ask for more feedback.
Over the last sixty years, the concept of Johari window had been applied in a wide variety of areas, including a few select attempts for organization as an entity. As a method to appreciate the source-of-value from analytics, here is yet another attempt to create Johari Window for organization an entity interacting with different stakeholders – Customers, Investors, Employees and Society.
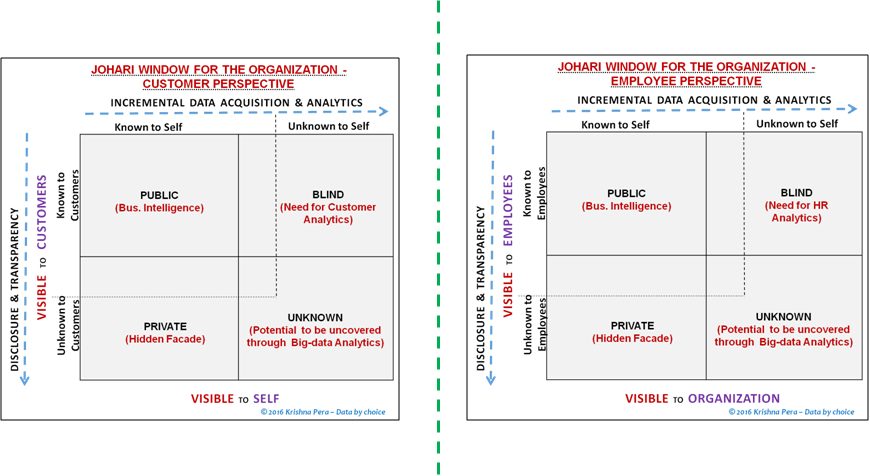
Consider the Johari window for an(y) Organization from the customer perspective: Among other things, the Blind area represents “customer’s perception of value” from the organizations’ products & services vis-à-vis competition that the Organization is ‘blind’ to. This represents an opportunity for unearthing hidden attributes influencing the customer behavior through Customer Analytics.
Similarly the Unknown area represents ‘the completely hidden reasons for customer behavior’ that neither the customer nor the organization is aware of… technically this area may have opportunities for huge upside to top-line or bottom-line which can be unearthed through Big-data Analytics.
The Johari window shown in the figure here could be redrawn with respect to any of the other Organizational stake-holders like Employees, Investors, Government or even Society at large. Consider the picture given here from the perspective of employees. Employee engagement and retention is one of the key issues for global organizations where the primary differentiator is the ‘quality of people’.
Large globally spread-out organizations at the highest level often lose sight of the intrinsic reasons for higher employee turn-over or lower motivation levels at times; why one product or geography of the organization does better than the others in terms of employee satisfaction levels. If the incentives for higher motivation levels in one part of the organization can be replicated to different parts of the organization with equal amount of success? Organizations often collect a large amount of data though employee-engagement surveys like Gallup Q12. The critics of these surveys complain that there is very little correlation between the Q12 score of an organization or a division and the actual business performance. They also quote instances of high Q12 score coupled by higher employee turn-over which turns the traditional logic upside down. HR analytics could help unearth the real reasons behind employee behavior in all such cases.
In search of Value from Analytics
Going back to the original question – How does one prioritize Analytics investments? Or how does one create a roadmap of investments for making one’s organization data-driven.
Assuming my original hypothesis is still sacrosanct; one must kick-start the exercise by identifying and prioritizing the opportunities where advanced analytics can make a material difference to the quality of decisions. In other words, one must identify 20% of the decisions which influence 80% of the Organizational outcomes, and prioritize them by decreasing order of relative value. Now the moot question is – By focusing on decisions – which perhaps represent “Known-known’s & Known-unknowns”, are we foregoing the seemingly much bigger prize being promised in “Unknown-unknowns”?
The real answer is – it depends…It really depends on maturity of the organization and the size of Unknown-unknowns.
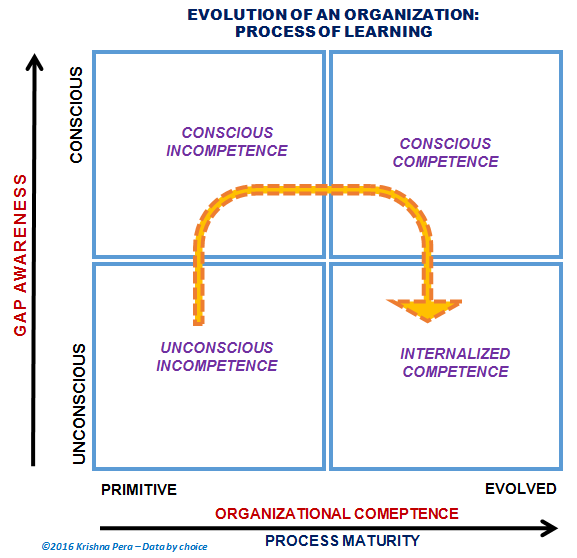
In theory: As the organizations mature, they tend to expand the region known as Known-known’s. They become more process-driven, would have more structured relevant data (captured-available with requisite granularity), and more importantly would have more structured decision-making.
I have also seen a few adaptations of “Four stages of competency” (attributed to Noel Burch of Gordon Training International & also to Abraham Maslow) to the evolution of Organization.
In reality: Organizations do not function in a static environment. Everything from Customer requirements to Competition, Governmental regulations and Compliance requirements are all dynamic in nature and can substantially change overnight. This is apart from the complexity that gets added from Organic and Inorganic growth, new products and new geographies being added every year. As a result, most growing Organizations are permanently on a catch-up mode with respect to their Process framework and IT systems maturity keeping pace with the Organizational growth.
In my experience, most faster-than-market growing organizations struggle with the legacy of multiple IT applications functioning as islands of information, multiple accounting systems, and multiple data definitions, with little or no data-governance in place.
Ideally they should take a pause every few years to consolidate the till-then-growth, and to integrate operations. The consolidation phase (pause in growth) helps in bringing the process & systems maturity closer to the Organizational needs.
A few years ago, when my work involved setting-up and scaling shared-services for multinationals, I used to talk about the need to create a Growth-template – a kind of process-systems combination, which can be used for quickly implementing-replicating the standard process & systems into any new geography, or product-line, the organization is expanding into. But all that may be a different story for a different time.
More at – www.databychoice.com
{kind=link}