
It is hardly possible in real life to develop a good machine learning model in a single pass. ML modeling is an iterative process and it is extremely important to keep track of your steps, dependencies between the steps, dependencies between your code and data files and all code running arguments. This becomes even more important and complicated in a team environment where data scientists’ collaboration takes a serious amount of the team’s effort.
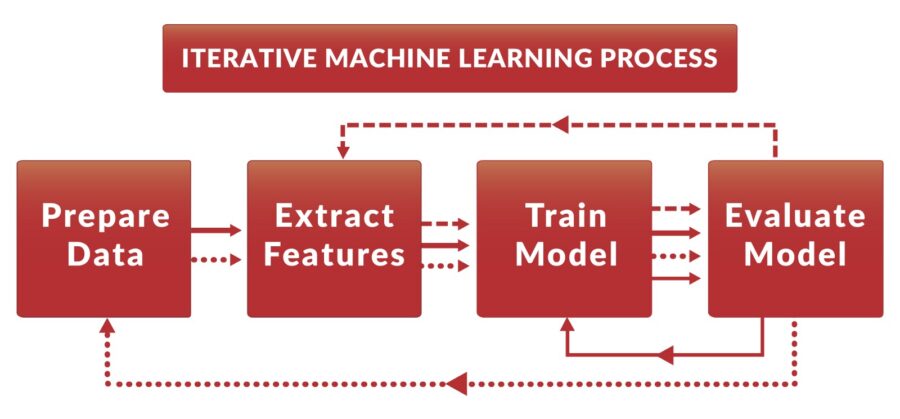
Today, we are pleased to announce the beta version release of new open source tool — data version control or DVC. DVC is designed to help data scientists keep track of their ML processes and file dependencies in the simple form of git-like commands: “dvc run python train_model.py data/train_matrix.p data/model.p”. Your existing ML processes can be easily transformed into reproducible DVC pipelines regardless of which programming language or tool was used.
This blog post walks you through an iterative process of building a machine learning model with DVC using stackoverflow posts dataset. First, you should initialize a Git repository and download a modeling source code that we will be using to show DVC in action:
$ mkdir myrepo
$ cd myrepo
$ mkdir code
$ wget -nv -P code/ https://s3-us-west-2.amazonaws.com/dvc-share/so/code/featurization.py \
https://s3-us-west-2.amazonaws.com/dvc-share/so/code/evaluate.py \
https://s3-us-west-2.amazonaws.com/dvc-share/so/code/train_model.py \
https://s3-us-west-2.amazonaws.com/dvc-share/so/code/split_train_te… \
https://s3-us-west-2.amazonaws.com/dvc-share/so/code/xml_to_tsv.py \
https://s3-us-west-2.amazonaws.com/dvc-share/so/code/requirements.txt
$ pip install -r code/requirements.txt
$ git init
$ git add code/
$ git commit -m ‘Download code’
The full pipeline could be built by running the bash code below. If you use Python version 3, please replace python to python3 and pip to pip3.
# Install DVC
$ pip install dvc
# Initialize DVC repository
$ dvc init
# Download a file and put to data/ directory.
$ dvc import https://s3-us-west-2.amazonaws.com/dvc-share/so/25K/Posts.xml.tgz data/
# Extract XML from the archive.
$ dvc run tar zxf data/Posts.xml.tgz -C data/
# Prepare data.
$ dvc run python code/xml_to_tsv.py data/Posts.xml data/Posts.tsv python
# Split training and testing dataset. Two output files.
# 0.33 is the test dataset splitting ratio. 20170426 is a seed for randomization.
$ dvc run python code/split_train_test.py data/Posts.tsv 0.33 20170426 data/Posts-train.tsv data/Posts-test.tsv
# Extract features from text data. Two TSV inputs and two pickle matrixes outputs.
$ dvc run python code/featurization.py data/Posts-train.tsv data/Posts-test.tsv data/matrix-train.p data/matrix-test.p
# Train ML model out of the training dataset. 20170426 is another seed value.
$dvc run python code/train_model.py data/matrix-train.p 20170426 data/model.p
# Evaluate the model by the testing dataset.
$ dvc run python code/evaluate.py data/model.p data/matrix-test.p data/evaluation.txt
# The result.
$ cat data/evaluation.txt
AUC: 0.596182
The one thing to wrap your head around is that DVC automatically derives the dependencies between the steps and builds the dependency graph (DAG) transparently to the user. This graph is used for reproducing parts of your pipeline which were affected by recent changes. In the next code sample we are changing feature extraction step of the pipeline and reproduce the final result. DVC derives that only three steps out of seven need to be rebuilt and runs these steps:
# Improve feature extraction step.
$ vi code/featurization.py
# Commit all the changes.
$ git commit -am “Add bigram features”
[master 50b5a2a] Add bigram features
1 file changed, 5 insertion(+), 2 deletion(-)
# Reproduce all required steps to get our target metrics file.
$ dvc repro data/evaluation.txt
Reproducing run command for data item data/matrix-train.p. Args: python code/featurization.py data/Posts-train.tsv data/Posts-test.tsv data/matrix-train.p data/matrix-test.p
Reproducing run command for data item data/model.p. Args: python code/train_model.py data/matrix-train.p 20170426 data/model.p
Reproducing run command for data item data/evaluation.txt. Args: python code/evaluate.py data/model.p data/matrix-test.p data/evaluation.txt
Data item “data/evaluation.txt” was reproduced.
# Take a look at the target metric improvement.
$ cat data/evaluation.txt
AUC: 0.627196
If you replace the input file that affects all the steps, then the entire pipeline will be reproduced.
# Replace small input dataset (25K items) to a bigger one (100K).
$ dvc remove data/Posts.xml.tgz
$ dvc import https://s3-us-west-2.amazonaws.com/dvc-share/so/100K/Posts.xml.tgz data/
# Reproduce the metric file.
$ dvc repro data/evaluation.txt
Reproducing run command for data item data/Posts.xml. Args: tar zxf data/Posts.xml.tgz -C data
Reproducing run command for data item data/Posts.tsv. Args: python code/xml_to_tsv.py data/Posts.xml data/Posts.tsv python
Reproducing run command for data item data/Posts-train.tsv. Args: python code/split_train_test.py data/Posts.tsv 0.33 20170426 data/Posts-train.tsv data/Posts-test.tsv
Reproducing run command for data item data/matrix-train.p. Args: python code/featurization.py data/Posts-train.tsv data/Posts-test.tsv data/matrix-train.p data/matrix-test.p
Reproducing run command for data item data/model.p. Args: python code/train_model.py data/matrix-train.p 20170426 data/model.p
Reproducing run command for data item data/evaluation.txt. Args: python code/evaluate.py data/model.p data/matrix-test.p data/evaluation.txt
Data item “data/evaluation.txt” was reproduced.
$ cat data/evaluation.txt
AUC: 0.633541
Not only can DVC streamline your work into a single, reproducible environment, it also makes it easy to share this environment by Git including the dependencies (DAG) — an exciting collaboration feature which gives the ability to reproduce the research results in different computers. Moreover, you can share your data files through cloud storage services like AWS S3 or GCP Storage since DVC does not push data files to Git repositories.
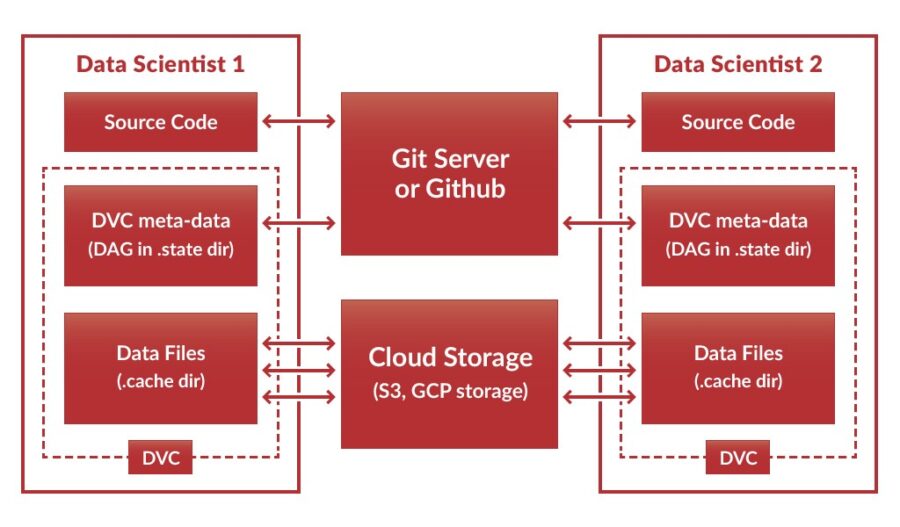
The code below shows how to share your code and DAG through the Git and data files through S3:
# Setup cloud settings. Example: Cloud = AWS, StoragePath=/dvc-share/projects/tag_classifier
$ vi dvc.conf
$ git commit -am “Set up AWS path”
[master ec994b6] Set up AWS path
1 file changed, 1 insertion(+), 1 deletion(-)
# Share the repository with the pipeline and the cloud settings.
$ git remote add origin https://github.com/dmpetrov/tag_classifier.git
$ git push -u origin master
# Share the most important data files.
$ dvc sync data/matrix-train.p data/matrix-test.p
Uploading cache file “.cache/matrix-train.p_1fa3a9b” to S3 “projects/tag_classifier/.cache/matrix-train.p_1fa3a9b”
Uploading completed
Uploading cache file “.cache/matrix-test.p_1fa3a9b” to S3 “projects/tag_classifier/.cache/matrix-test.p_1fa3a9b”
Uploading completed
Now, another data scientist can use this repository and reproduce the data files the same way you just did. If she doesn’t want (or has not enough computational resources) to reproduce everything, she can sync and lock shared data files. After that, only the last steps of the ML process will be reproduced.
# Get the repository.
$ git clone https://github.com/dmpetrov/tag_classifier.git
# Sync the data files from S3.
$ dvc sync data/
Uploading cache file “.cache/empty_0000000” to S3 “projects/tag_classifier/.cache/empty_0000000”
Uploading completed
Downloading cache file from S3 “dvc-share/projects/tag_classifier/.cache/matrix-test.p_1fa3a9b”
Downloading completed
Downloading cache file from S3 “dvc-share/projects/tag_classifier/.cache/matrix-train.p_1fa3a9b”
Downloading completed
# Lock the reproduction process in the feature extraction step
# since these data files were synced.
$ dvc lock data/matrix-t*
Data item data/matrix-test.p was locked
Data item data/matrix-train.p was locked
# Improve the model.
$ vi code/train_model.py
$ git commit -am “Tune the model”
[master 77e2943] Tune the model
1 file changed, 1 insertion(+), 1 deletion(-)
# Reproduce required steps of the pipeline.
$ dvc repro data/evaluation.txt
Reproducing run command for data item data/model.p. Args: python code/train_model.py data/matrix-train.p 20170426 data/model.p
Reproducing run command for data item data/evaluation.txt. Args: python code/evaluate.py data/model.p data/matrix-test.p data/evaluation.txt
Data item “data/evaluation.txt” was reproduced.
$ cat data/evaluation.txt
AUC: 0.670531
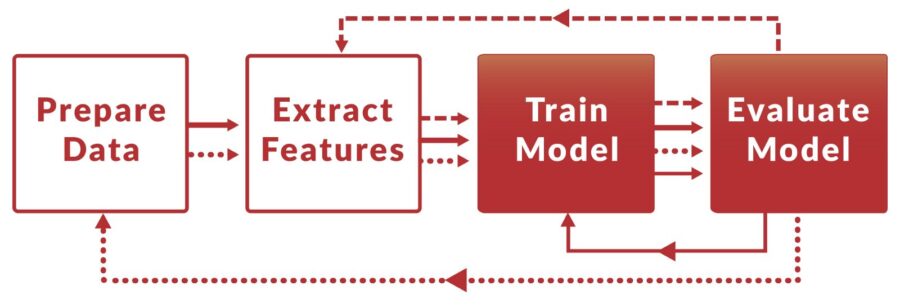
The steps that were reproduced (red):
Conclusion
Thus, the model can be improved iteratively and DVC simplifies the iterative ML process and aids collaboration between data scientists.
We are very interested in your opinion and feedback. Please post your comments here or contact us in twitter.
The original GITHUB repository can be found here and the original blogpost here.
{kind=link}