Context Matters When Text Mining
Many times the most followed approach can result in failure. The reason has more to do with thinking that one approach works in all cases. This is specially true in text mining. For instance, a common approach in clustering documents is to create tf-idf matrix for all documents, use SVD or other dimension reduction algorithm and then use a clustering. In most cases, this will work; However, as I will present here, there are instances where this process will not provide the intended result. It will not work because the subject characteristic, or the context where the approach is used. Recipe reviews is one of these instances.
To show the importance of context driven text mining, I will use recipe reviews as example, more precisely Enchiladareviews. You can find the cleaned dataset (tokenized by sentence structure and words, stop-words removed, and lower cased words) in github, and full description in my previous blog. I sampled 239 reviews, or 1616 sentences.
Dimension Reduction With SVD
If the questions of interest are: “What differentiate these reviews?” “Can we find terms associations?” then one can assume that pre-knowledge of what the reviews contain may be irrelevant. One may even go further and assume that each review is a document, and treat the reviews as a bag of words instead of a bag of sentences. To do so, I preprocessed the 239 Enchilada reviews.
The preprocessing goes as follows:
- tokenize by words
- remove punctuations
- stem
- keep the 300 most frequent words. This step is optional
- Build tf-idf matrix
- Use SVD to reduce further the bag of words
The final result is 108 words:
The recipe received 5 stars from reviews, and the top 108 words attest to this. You can find the words love, like, thank, good, 5, star, nice, yummy, and more that attest that a lot of reviewers liked this recipe. However, if they liked it why are there ingredients not in the original ingredients list: ginger, an broccoli, and why are there words not related to sentiment? Still, now SVD helps in the building of a LSA (latent Semantic Analysis) to find associations or to compare terms in documents, or documents. LSA found the association between garlic and clove, and 5 and star. As expected, many other association made no sense. For instance, bean was associated with chose, peeler, and pot. While one can see the association between bean and pot, one can be perplexed by the association between been and peeler.
From the reduced number of terms, one can build an unsupervised classifier with SOM or K-mean. SOM produced the following:

Analysis of the content of the clusters may provide an insight on the reviews differences. What do these clusters contain? I checked them out but could not figure out what differentiated them. A deeper analysis of the content of these clusters may provide an insight on the reviews. However, is there a simpler a more straight forward approach to finding an insight? You will agree the findings were limited and of little use: clustering added more questions than answers; and LSA found some associations but missed most. You can see that most people liked the dish because the positive sentiments words are among the top 108 frequent words, but also, among these words, you can find words with no connection to sentiment: garlic, thicken, to name few. This approach has not been able to capture the nuances within the reviews. I have set it up to fail from the beginning and be able answer partially to following question: “Is there something that one may learn from analyzing reviews?”
Context
To answer “Is there something that one may learn from analyzing reviews?”, I decided to parse the sentences within the reviews. From the WordCloud and the top frequent words I could see that the content of a review goes beyond sentiments. The sentences without sentiments had references to ingredients. Hence, I decided the increase granularity of my dataset. I tokenized the reviews into sentences, and sentences into words. I also removed stop words. I didn’t bother stemming, or find POS. Then I decided to map sentences with ingredients to 1 and without ingredients with 0. This resulted in 794 sentences classified as sentiments, and 822 classified as others–very even number.
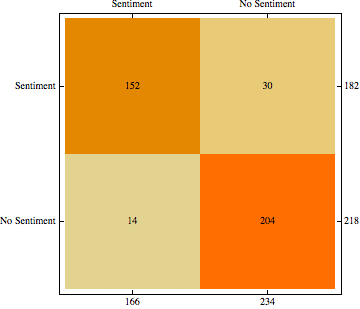
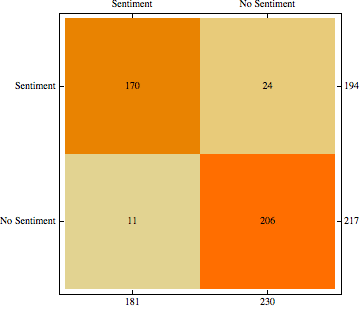
There were 1616 sentences, and I divided them into training set, testing set, and validation set with sizes 800, 400, and 415, respectively; I built a Markov model, which works with tokenized text. The accuracy of the model on the testing data set was 89% with a precision of 83.51% and recall of 91.56% for sentiment sentences or FScore of 87.35% (see left Figure). For others, the precision and recall were 93.58% and 87.18%, respectively, or FScore of 90.27 (see right Figure). The performance was still consistent when validation data set was introduced–accuracy of 91.48%. These results were achieved with no optimization. The accuracy of the model attest that sentences in reviews are not all sentiment, and a pattern does exists.
Now, if you also take into consideration that recipes and reviews have ingredients, then your next question may be: if one keeps only the ingredients mentioned what can one learn? Keeping only ingredients mentioned in sentences, you can draw a graph, and then create a community graph (clustering in graph into groups). As you can see, associations are found that LSA cannot detect. For instance, chicken is highly connected to cumin, garlic, and onion. Many reviews combined these ingredients together. One can also see green chili, tomato, and serrano tightly connected. In cooking enchilada chili and tomatoes tend to be added together. It also looks like that ingredients that didn’t map to any cluster were put together: potato, oregano, and tomatillo. Hence, more complex associations can be found that LSA will not be able to do without large a text corpus. Yes, I didn’t have to create tf-idf matrix, but I still needed to have an ingredient dictionary; which means taking context into consideration.
Conclusion
Just by knowing the context of your subject you can extract a lot useful information than you would if you just followed a script. For instance, finding out that reviews are not just opinions in the Enchilada recipe, you found out that you can classify the sentences within reviews as sentiment or not and find out that half of them contain information needed to improve your dish. By mapping ingredients in sentences to a graph and applying a community clustering, you find which ingredients associate with each other, or are mentioned together. These are only few findings. For instance, what if I analyzed all the sentences that are not sentiment, and created a direct graph?




{kind=link}