New & Notable
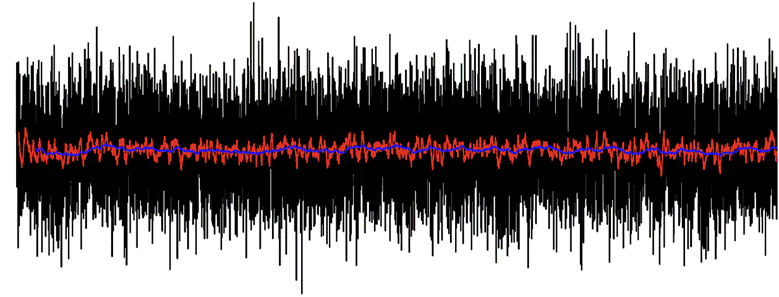
Secrets of time series modeling: Nested cross-validation
Vlad Johnson | September 22, 2025 at 2:55 pm
How business leaders are using AI to make data-driven decisions
Edward Nick | September 10, 2025 at 10:40 amTop Webinar

Recently Added
Secrets of time series modeling: Nested cross-validation
Vlad Johnson | September 22, 2025 at 2:55 pmWelcome to the series of articles on the secrets of time series modeling. Today’s edition features the nested cross-va...
How business leaders are using AI to make data-driven decisions
Edward Nick | September 10, 2025 at 10:40 amIntuition alone is no longer enough for effective leadership in the modern business world. Business leaders increasingly...

The data platform debt you don’t see coming
Saqib Jan | August 28, 2025 at 2:05 pmData Platform Debt...

Designing AI factories: Purpose-built, on-prem GPU data centers
Martin Summer | August 26, 2025 at 2:39 pmDiscover how purpose-built AI factories are transforming on-premises GPU data centers for high-performance AI workloads,...

How diagnosis image annotation turns scans into insights
Rayan Potter | August 26, 2025 at 12:40 pmA radiologist looks at hundreds of CT images to find a tiny shadow that could be cancer. At these moments, every pixel m...

How AI shapes the future of work with superworkers
Tarique | August 26, 2025 at 9:04 amThe dialogue surrounding AI often raises anxiety: Will I be automated out of a job? The fact is, things are far more opt...
Language Models: A 75-Year Journey That Didn’t Start With Transformers
Vincent Granville | August 22, 2025 at 1:13 amIntroduction Language models have existed for decades — long before today’s so-called “LLMs.” In the 1990s, IBM�...

Ranking GPT-5 against LLMs
David Stephen | August 14, 2025 at 10:59 amAI benchmarks have created a false impression about how to evaluate AI models: test AI for complex questions that sever...

Computing infrastructure challenges in AI workloads
Martin Summer | August 12, 2025 at 11:29 amExplore the critical computing infrastructure challenges in AI workloads, from scalability and storage to network perfor...

A tech debt fighting champion for developers
Ernesto Tagwerker | August 12, 2025 at 9:14 amTechnical debt occurs when best practices are ignored as IT solutions are built. In a survey of 500+ IT pros conducted b...
New Videos

Swiss Vault is bringing hyperscaler power to everyone
Interview with Bhupinder Bhullar In a world increasingly dominated by AI, massive data creation, and energy-hungry compute infrastructure, the question isn’t just how to store…

A/B Testing Pitfalls – Interview w/ Sumit Gupta @ Notion
Interview w/ Sumit Gupta – Business Intelligence Engineer at Notion In our latest episode of the AI Think Tank Podcast, I had the pleasure of sitting…

Davos World Economic Forum Annual Meeting Highlights 2025
Interview w/ Egle B. Thomas Each January, the serene snow-covered landscapes of Davos, Switzerland, transform into a global epicenter for dialogue on economics, technology, and…