
This is not a repository of traditional questions that you can find everywhere on the Internet. Instead, it is a short selection of problems that require outside-the-box thinking. They come from my own projects, focusing on recent methods not taught anywhere. Some are related to new, efficient algorithms, sometimes not yet implemented by large companies. I also provide my answers. It would be interesting to compare them to OpenAI answers.
1. How to build knowledge graphs with embedded dictionaries in Python?
One way to do it is to have a hash (dictionary in Python, also called key-value table) where the key is a word, token, concept, or category, for instance “mathematics”. The value — one per key — is itself a hash: the nested hash. The key in the nested hash is also a word, for instance a word such as “calculus”, related to the parent key in the parent hash. And the value is a weight: high for “calculus” since “calculus” and “mathematics” are related and frequently found together, and conversely, low for “restaurants” as “restaurants” and “mathematics” are rarely found together.
In LLMs, the nested hash may be an embedding. Because the nested hash does not have a fixed number of elements, it handles sparse graphs far better than vector databases or matrices. It leads to much faster algorithms requiring very little memory.
2. How to perform hierarchical clustering when the data consists of 100 million keywords?
You want to cluster keywords. For each pair of keywords {A, B}, you can compute the similarity between A and B, telling how similar the two words are. The goal is to produce clusters of similar keywords.
Standard Python libraries such as Sklearn offer agglomerative clustering, also called hierarchical clustering. However, they would typically need a 100 million x 100 million distance matrix in this example. This won’t work. In practice, random words A and B are rarely found together, thus the distance matrix is extremely sparse. The solution consists of using methods adapted to sparse graphs, using for instance the nested hashes discussed in question 1. One such method is clustering based on detecting the connected components in the underlying graph.
3. How to crawl a large repository such as Wikipedia, to retrieve the underlying structure, not just separate entries?
These repositories all have structural elements embedded into the web pages, making the content a lot more structured than it seems at first glance. Some structure elements are invisible to the naked eye, such as metadata. Some are visible and also present in the crawled data, such as indexes, related items, breadcrumbs, or categorization. You can retrieve these elements separately to build a good knowledge graph or a taxonomy. But you may need to write your own crawler from scratch rather than relying on (say) Beautiful Soup. LLMs enriched with structural information, such as xLLM (see here), offer superior results. What’s more, you can use the structure retrieved from an external source, to augment your crawled data if your repository truly lacks any structure. This is called structure augmentation.
4. How to enhance LLM embeddings with long and contextual tokens?
Embeddings consists of tokens; these are among the smallest text elements that you can find in any document. But it does not need to be that way. Instead of having two tokens, say ‘data’ and ‘science’, you could have four: ‘data^science’, ‘data’, ‘science’, and ‘data~science’. The last one indicates that the whole word ‘data science’ was found. The first one means that both ‘data’ and ‘science’ were found, but at random locations in (say) a given paragraph, not at adjacent locations. Such tokens are called multi-tokens or contextual tokens. They offer some good redundancy, but if you are not careful, you can end up with gigantic embeddings. The solution consists of purging useless tokens (keeping the longest ones) and working with variable size embeddings, see here. Contextual contents can reduce LLM hallucinations.
5. How to implement self-tuning to eliminate many issues connected to model evaluation and training?
This works with systems based on explainable AI, by contrast to neural network black boxes. Allow the user of your app to select hyperparameters and flag those that he likes. Use that information to find ideal hyperparameters and set them as default. This is automated reinforcement learning based on user input. It also allows the user to choose his favorite sets depending on the desired results, making your app customizable. In LLMs, allowing the user to choose a specific sub-LLM (based for instance on the type of search or category), further boosts performance. Adding a relevancy score to each item in the output results, also help fine-tuning your system.
6. How to increase the speed of vector search by several orders of magnitude?
In LLMs, working with variable-length embeddings dramatically reduces the size of the embeddings. Thus, it accelerates search to find back-end embeddings similar to those captured in the front-end prompt. However, it may require a different type of database, such as key-value tables. Reducing the size of the token and embedding tables is another solution: in a trillion-token system, 95% of the tokens are never fetched to answer a prompt. It is just noise: get rid of them. Working with contextual tokens (see question 4) is another way to store information in a more compact way. In the end, you use approximate nearest neighbor search (ANN) on compressed embeddings to do the search. A probabilistic version (pANN) can run a lot faster, see here. Finally, use a cache mechanism to store the most frequently accessed embeddings or queries, to get better real-time performance.
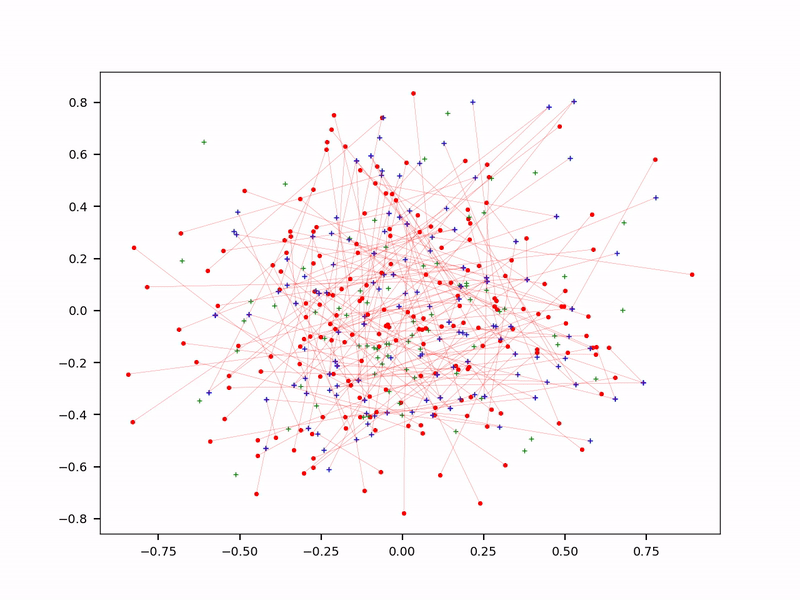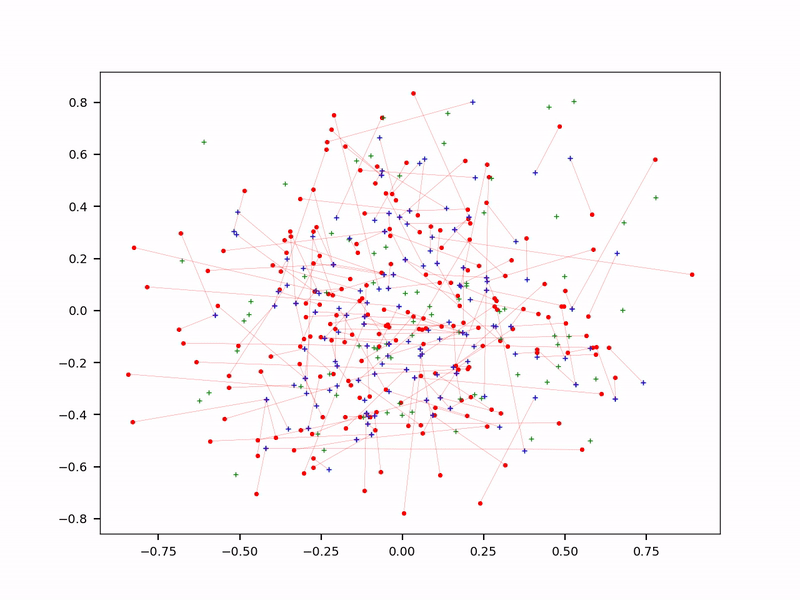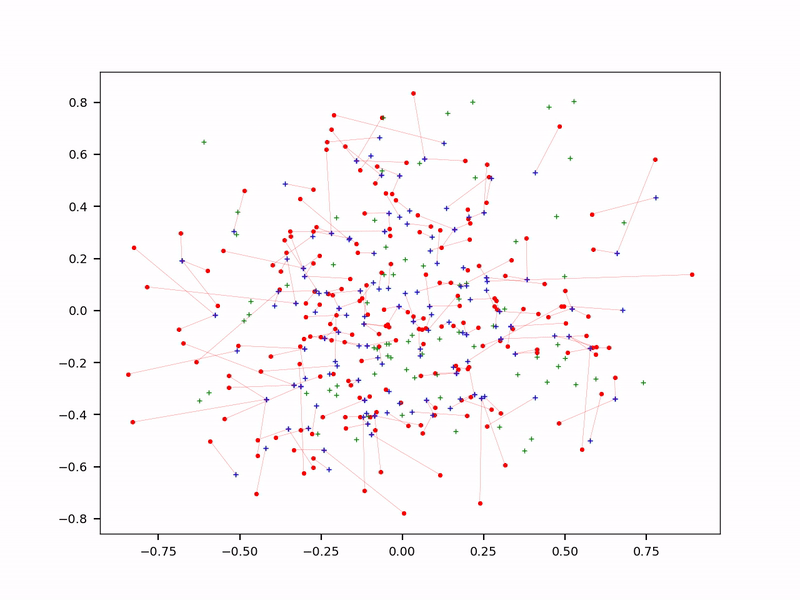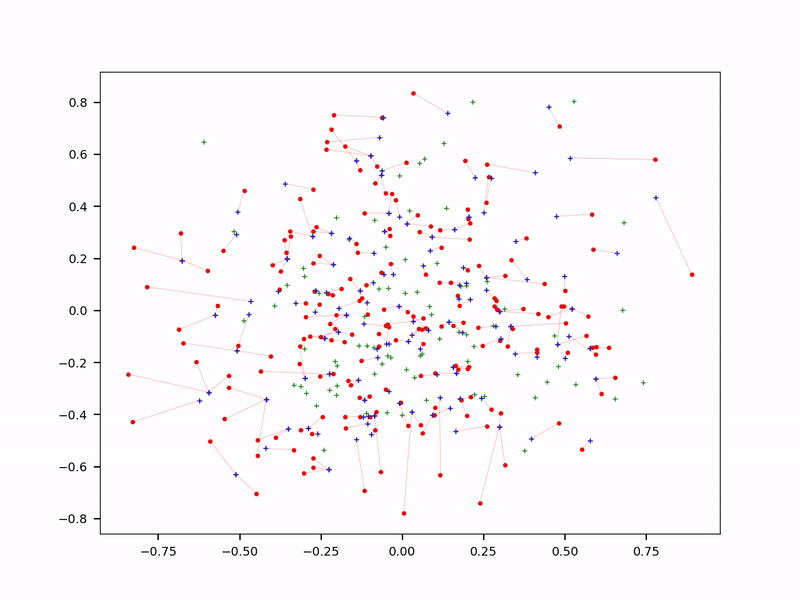
In some of my applications, reducing the size of the training set by 50% led to better results, with less overfitting. In LLMs, choosing a few great input sources does better than crawling the whole Internet. And having a specialized LLM for each top category, as opposed to one-size-fits-all, further reduces the number of embeddings: each prompt targets a specific sub-LLM, not the entire database.
7. What is the ideal loss function to get the best results out of your model?
The best solution is to use the model evaluation metric as the loss function (when possible, in supervised learning). The reason why this is rarely if ever done is because you need a loss function that can be updated extremely fast each time a neuron gets activated in your neural network. Another solution, in the context of neural networks, consists in computing the evaluation metric after each epoch, and keep the solution generated at the epoch with best evaluation score, as opposed to the epoch with minimal loss.
I am currently working on a system where the evaluation metric and loss function are identical. Not based on neural networks. Initially, my evaluation metric was the multivariate Kolmogorov-Smirnov distance (KS), based on the difference between two empirical cumulative distributions: observed in the training set, versus generated. It is extremely hard to make atomic updates to KS, on big data, without massive computations. It makes KS unsuitable as a loss function because you need billions of atomic updates. But by changing the cumulative distribution to the probability density function with millions of bins (the actual change is more complicated than that), I was able to come up with a great evaluation metric, which also works very well as a loss function.
Author

Vincent Granville is a pioneering GenAI scientist and machine learning expert, co-founder of Data Science Central (acquired by a publicly traded company in 2020), Chief AI Scientist at MLTechniques.com and GenAItechLab.com, former VC-funded executive, author (Elsevier) and patent owner — one related to LLM. Vincent’s past corporate experience includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET. Follow Vincent on LinkedIn.
{kind=link}