
This is the third and final article in this series, featuring some of the most powerful features to improve RAG/LLM performance. In particular: speed, latency, relevancy (hallucinations, lack of exhaustivity), memory use and bandwidth (cloud, GPU, training, number of parameters), security, explainability, as well as incremental value for the user. I published the first part here, and the second part here. I implemented these features in my xLLM system. See details in my recent book, here.
22. Self-tuning and customization
If your LLM – or part of it such as a sub-LLM – is light enough so that your backend tables and token lists fit in memory occupying little space, then it opens up many possibilities. For instance, the ability to fine-tune in real time, either via automated algorithms, or by letting the end-user doing it on his own. The latter is available in xLLM, with intuitive parameters: when fine-tuning, you can easily predict the effect of lowering or increasing some values. In the end, two users with the same prompt may get different results if working with different parameter sets. It leads to a high level of customization.
Now if you have a large number of users, with a few hundred allowed to fine-tune the parameters, you can collect valuable information. It becomes easy to detect the popular combinations of values from the customized parameter sets. The system can auto-detect the best parameter values and offer a small selection as default or recommended combinations. More can be added over time based on user selection, leading to organic reinforcement leaning and self-tuning.
Self-tuning is not limited to parameter values. Some metrics such as PMI (a replacement to the dot product and cosine similarity) depend on some parameters that can be fine-tuned. But even the whole formula itself (a Python function) can be customized.
23. Local, global parameters, and debugging
In multi-LLM systems (sometimes called mixture of experts), whether you have a dozen or hundreds of sub-LLMs, you can optimize each sub-LLM locally, or the whole system. Each sub-LLM has its own backend tables to deal with the specialized corpus that it covers, typically a top category. However, you can have either local or global parameters:
- Global parameters are identical for all sub-LLMs. They may not perform as well as local parameters, but they are easier to maintain. Also, they can be more difficult to fine-tune. However, you can fine-tune them first on select sub-LLMs, before choosing the parameter set that on average, performs best across multiple high-usage sub-LLMs.
- Local parameters boost performance but require more time to fine-tune, as each sub-LLM has a different set. At the very least, you should consider using ad-hoc stopwords lists for each sub-LLM. These are built by looking at top tokens prior to filtering or distillation, and letting an expert determine which tokens are worth ignoring, for the topic covered by the sub-LLM in question.
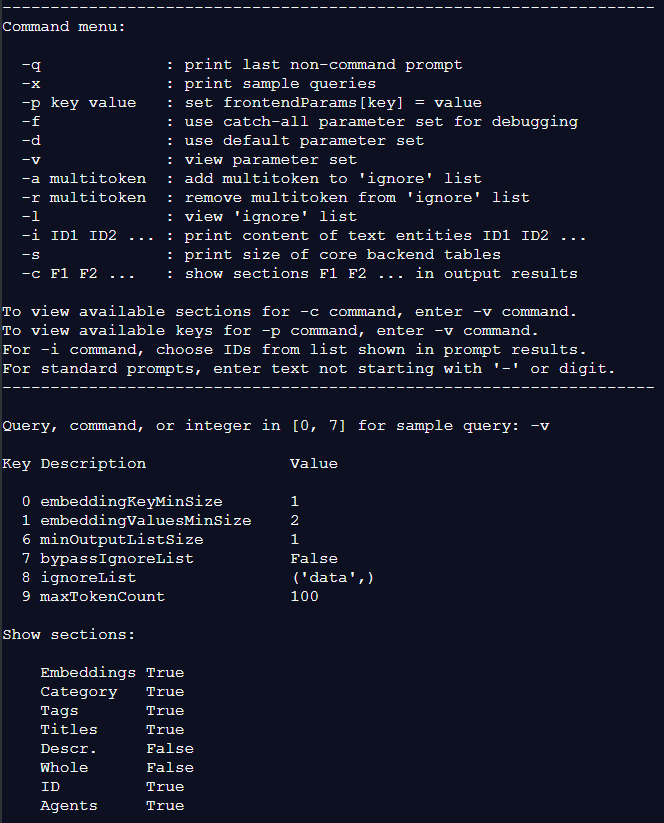
You can have a mix of global and local parameters. In xLLM, there is a catch-all parameter set that returns the maximum output you can possibly get from any prompt. It is the same for all sub-LLMs. See option -f on the command prompt menu in Figure 1. You can use this parameter set as starting point and modify values until the output is concise enough and shows the most relevant items at the top. The-f option is also used for debugging.
24. Displaying relevancy scores, and customizing scores
By showing a relevancy score to each item returned to a prompt, it helps the user determine which pieces of information are most valuable, or which text entities to view (similar to deciding whether clicking on a link or not, in classic search). It also helps with fine-tuning, as scores depend on the parameter set. Finally, some items with lower score may be of particular interest to the user; it is important not to return top scores exclusively. We are all familiar with Google search, where the most valuable results typically do not show up at the top.
Currently, this feature is not yet implemented in xLLM. However, many statistics are attached to each item, from which one can build a score. The PMI is one of them. In the next version, a custom score will be added. Just like the PMI function, it will be another function that the user can customize.
25. Intuitive hyperparameters
If your LLM is powered by a deep neural network (DNN), parameters are called hyperparameters. It is not obvious how to fine-tune them jointly unless you have considerable experience with DNNs. Since xLLM is based on explainable AI, parameters– whether backend or frontend– are intuitive. You can easily predict the impact of lowering or increasing values. Indeed, the end-user is allowed to play with frontend parameters. These parameters typically put restrictions on what to display in the results. For instance:
- Minimum PMI threshold: the absolute minimum is zero, and depending on the PMI function, the maximum is one. Do not display content with a PMI below the specified threshold.
- Single tokens to ignore because they are found in too many text entities, for instance ‘data’ or ‘table’. This does not prevent ‘data governance’ from showing up, as it is a multitoken of its own.
- Maximum gap between two tokens to be considered as related. Also, list of text separators to identify text sub-entities (a relation between two tokens is established anytime they are found in a same sub-entity).
- Maximum number of words allowed per multitoken. Minimum and maximum word count for a token to be integrated in the results.
- Amount of boost to add to tokens that are also found in the knowledge graph, taxonomy, title, or categories. Amount of stemming allowed.
26. Sorted n-grams and token order preservation
To retrieve information from the backend tables in order to answer a user query (prompt), the first step consists of cleaning the query and breaking it down into sub-queries. The cleaning consists of removing stopwords, some stemming, adding acronyms, auto-correct and so on. Then only keep the tokens found in the dictionary. The dictionary is a backend table built on the augmented corpus.
Let’s say that after cleaning, we have identified a subquery consisting of tokens A, B, C, D, in that order in the original prompt. For instance (A, B, C, D) = (‘new’, ‘metadata’, ‘template’, ‘description’). The next step consists in looking at all 15 combinations of any number of these tokens, sorted in alphabetical order. For instance, ‘new’, ‘metadata new’, ‘description metadata’, ‘description metadata template’. These combinations are called sorted n grams. In the xLLM architecture, there is a key-value backend table, where the key is a sorted n-gram. And the value is a list of multitokens found in the dictionary (that is, in the corpus), obtained by rearranging the tokens in the parent key. For a key to exist, at least one rearrangement must be in the dictionary. In our example, ‘description template’ is a key (sorted n-gram) and the corresponding value is a list consisting of one element: ‘template description’ (a multitoken).
This type of architecture indirectly preserves to a large extent the order in which tokens show up in the prompt, while looking for all potential re-orderings in a very efficient way. In addition, it allows you to retrieve in the corpus the largest text element (multitoken) matching, up to token order, the text in the cleaned prompt. Even if the user entered a token not found in the corpus, provided that an acronym exists in the dictionary.
27. Blending standard tokens with tokens in the knowledge graph
In the corpus, each text entity is linked to some knowledge graph elements: tags, title, category, parent category, related items, and so on. These are found while crawling and consist of text. I blend them with the ordinary text. They end up in the embeddings, and contribute to enrich the multitoken associations, in a way similar to augmented data. They also add contextual information not limited to token proximity.
28. Boosted weights for knowledge-graph tokens
Not all tokens are created equal, even those with identical spelling. Location is particularly important: tokens can come from ordinary text, or from the knowledge graph, see feature # 27. The latter always yields higher quality. When a token is found while parsing a text entity, its counter is incremented in the dictionary, typically by 1. However, in the xLLM architecture, you can add an extra boost to the increment if the token is found in the knowledge graph, as opposed to ordinary text. Some backend parameters allow you to choose how much boost to add, depending on whether the graph element is a tag, category, title, and so on. Another strategy is to use two counters: one for the number of occurrences in ordinary text, and a separate one for occurrences in knowledge graph.
29. Versatile command prompt
Most commercial LLM apps that I am familiar with offer limited options besides the standard prompt. Sure, you can input your corpus, work with an API or SDK. In some cases, you can choose specific deep neural network (DNN) hyperparameters for fine-tuning. But for the most part, they remain a Blackbox. One of the main reasons is that they require training, and training is a laborious process when dealing with DNNs with billions of weights.
With in-memory LLMs such as xLLM, there is no training. Fine-tuning is a lot easier and faster, thanks to explainable AI: see feature # 25. In addition to standard prompts, the user can enter command options in the prompt box, for instance -p key value to assign value to parameter key. See Figure 1. The next prompt will be based on the new parameters, without any delay to return results based on the new configuration.
There are many other options besides fine-tuning: an agent box allowing the user to choose a specific agent, and a category box to choose which sub-LLMs you want to target. You can even check the sizes of the main tables (embeddings, dictionary, contextual), as they depend on the backend parameters.
30. Boost long multitokens and rare single tokens
I use different mechanisms to give more importance to multitokens consisting of at least two terms. The higher the number of terms, the higher the importance. For instance, if a cleaned prompt contains the multitokens (A, B), (B, C), and (A, B, C) and all have the same count in the dictionary (this happens frequently), xLLM with display results related to (A, B, C) only, ignoring (A, B) and (B, C). Some frontend parameters allow you to set the minimum number of terms per multitoken, to avoid returning generic results that match just one token. Also, the PMI metric can be customized to favor long multi-tokens.
Converserly, some single tokens, even consisting of one or two letters depending on the sub-LLM, may be quite rare, indicating that they have high informative value. There is an option in xLLM not to ignore single tokens with fewer than a specified number of occurrences.
Note that in many LLMs on the market, tokens are very short. They consist of parts of a word, not even a full word, and multitokens are absent. In xLLM, very long tokens are favored, while tokens that are less than a word, don’t exist. Yet, digits like 1 or 2, single letters, IDs, symbols, codes, and even special characters can be token if they are found as is in the corpus
About the Author

Vincent Granville is a pioneering GenAI scientist and machine learning expert, co-founder of Data Science Central (acquired by a publicly traded company in 2020), Chief AI Scientist at MLTechniques.com and GenAItechLab.com, former VC-funded executive, author (Elsevier) and patent owner — one related to LLM. Vincent’s past corporate experience includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET. Follow Vincent on LinkedIn.
{kind=link}