
Check out Part I of this article for background information, and to discover the first 12 uses of statistical modeling. Here we list another 12 popular uses of statistical, data science, machine learning, optimization, graph theory, mathematical and operations research techniques.
13. Simulations
Monte-Carlo simulations are used in many contexts: to produce high quality pseudo-random numbers, in complex settings such as multi-layer spatio-temporal hierarchical Bayesian models, to estimate parameters (see picture below), to compute statistics associated with very rare events, or even to generate large amount of data (for instance cross and auto-correlated time series) to test and compare various algorithms, especially for stock trading or in engineering.
14. Churn Analysis
Customer churn analysis helps you identify and focus on higher value customers, determine what actions typically precede a lost customer or sale, and better understand what factors influence customer retention. Statistical techniques involved include survival analysis (see Part I of this article) as well as Markov chains with four states: brand new customer, returning customer, inactive (lost) customer, and re-acquired customer, along with path analysis (including root cause analysis) to understand how customers move from one state to another, to maximize profit. Related topics: customer lifetime value, cost of user acquisition, user retention.
15. Inventory management
Inventory management is the overseeing and controlling of the ordering, storage and use of components that a company will use in the production of the items it will sell as well as the overseeing and controlling of quantities of finished products for sale. Inventory management is an operations research technique leveraging analytics (time series, seasonality, regression), especially for sales forecasting and optimum pricing – broken down per product category, market segment, and geography. It is strongly related to pricing optimization (see item #17). This is not just for brick and mortar operations: inventory could mean the amount of available banner ad slots on a publisher website in the next 60 days, with estimates of how much traffic (and conversions) each banner ad slot is expected to deliver to the potential advertiser. You don’t want to over-sell or under-sell this virtual inventory, and thus you need good statistical models to predict the web traffic and conversions (to pre-sell the inventory), for each advertiser category.
16. Optimum Bidding
This is an example of automated, black-box, machine-to-machine communication system, sometimes working in real time, via various API’s. It is backed by statistical models. Applications include detecting and purchasing the right keywords at the right price on Google AdWords, based on expected conversion rates for millions of keywords, most of them having no historical data; keywords are categorized using an indexation algorithm (see item #18 in this article) and aggregated into buckets (categories) to get some historical data with statistical significance, at the bucket level. This is a real problem for companies such as Amazon or eBay. Or it could be used as the core algorithm for automated high frequency stock trading.
17. Optimum Pricing
While at first glance it sounds like an econometric problem handled with efficiency curves, or even a pure business problem, it is highly statistical in nature. Optimum pricing takes into account available and predicted inventory, production costs, prices from competitors, and profit margins. Price elasticity models are often used to determine how high prices can be boosted before reaching strong resistance. Modern systems offer prices-on-demand, in real time, for instance when booking a flight or an hotel room. User-dependent pricing – a way to further optimize pricing, offering different prices based on user segment – is a controversial issue. It is accepted in the insurance industry: bad car drivers paying more than good ones for the same coverage, or smokers / women / old people paying a different fee for healthcare insurance (this is the only price discrimination allowed by Obamacare).
18. Indexation
Any system based on taxonomies use an indexation algorithm, created to build and maintain the taxonomy. For instance product reviews (both products and reviewers must be categorized using an indexation algorithm, then mapped onto each other), scoring algorithms to detect the top people to follow in a specific domain (click here for details), digital content management (click here for details, read part 2), and of course search engine technology. Indexation is a very efficient clustering algorithm, and the time used to index massive amounts of content grows linearly – that is very fast – with the size of your dataset. Basically, it relies on a few hundreds categories manually selected after parsing tons of documents, extracting billions of keywords, filtering them, producing a keyword frequency table, and focusing on top keywords. Indexation is also used in systems that provide related keywords associated with user-entered keywords, for instance in this example.
Last but not least, an indexation algorithm can be used to automatically create an index for any document – report, article, blog, website, data repository, metadata, catalog, or book. Indeed, that’s the origin of the word indexation. Surprisingly, publishers still pay people today for indexing jobs: you can find these jobs listed on the American Society for Indexing website. This is an opportunity for data scientist entrepreneurs: offering publishers a software that does this job automatically, at a fraction of the cost.
19. Search Engines
Good search engine technology relies heavily on statistical modeling. Enterprise search engines help companies – for instance Amazon – sell their products, by providing users with an easy way to find them. Our own Data Science Central search is of high quality (superior to Google search), and one of the most used features on our website. The core algorithm used in any search engine is an indexation (see item #19 in this article) or automated tagging system. Google search could be improved as follows: (1) eliminate page rank – this algorithm has been fooled by cheaters developing link farms and other web spam, (2) add new content more frequently in your index to make search results less static, less frozen in time, (3) show more relevant articles using better user / search keyword / landing page matching algorithms which ultimately means better indexation systems, and (4) use better attribution models to show the source of an article, not copies published on LinkedIn or elsewhere. (this could be as simple as putting more weights on small publishers, and identifying the first occurrence of an article, that is, time stamp detection and management).
20. Cross-Selling
Usually based on collaborative filtering algorithms, the idea is to find – especially in retail – which products to sell to a client based on recent purchases or interests. For instance, trying to sell engine oil to a customer buying gasoline. In banking, a company might want to sell several services: a checking account first, then a saving account, then a business account, then a loan and so on, to a specific customer segment. The challenge is to identify the correct order in which products must be promoted, the correct customer segments, and the optimum time lag between the various promotions. Cross-selling is different from up-selling.
21. Clinical trials
Clinical trials are experiments done in clinical research, usually involving small data. Such prospective biomedical or behavioral research studies on human participants are designed to answer specific questions about biomedical or behavioral interventions, including new treatments and known interventions that warrant further study and comparison. Clinical trials generate data on safety and efficacy. Major concerns include how test patients are sampled (especially if they are compensated), conflict of interests in these studies, and the lack of reproducibility.
22. Multivariate Testing
Multivariate testing is a technique for testing an hypothesis in which multiple variables are modified. The goal is to determine which combination of variations performs the best out of all of the possible combinations. Websites and mobile apps are made of combinations of changeable elements, that are optimized using multivariate testing. This involves careful design-of-experiment, and the tiny, temporary difference (in yield or web traffic) between two versions of a webpage might not have statistical significance. While ANOVA and tests of hypotheses are used by industrial or healthcare statisticians for multivariate testing, we have developed systems that are model-free, data-driven, based on data binning and model-free confidence intervals (click here and here for details). Stopping a multivariate testing experiment (they usually last 14 days for web page optimization) as soon as the winning combination is identified, helps save a lot of money. Note that external events – for instance an holiday or some server outage – can impact the results of multivariate testing, and need to be addressed.
23. Queuing Systems
A queue management system is used to control queues. Queues of people form in various situations and locations in a queue area, for instance in a call center. The process of queue formation and propagation is defined as queuing theory. Arrival of people in a queue is typically modeled using a Poisson process, with time to serve a client modeled using an exponential distribution. While being a statistical problem, it is considered to be part of operations research.
24. Supply Chain Optimization
Supply chain optimization is the application of processes and tools to ensure the optimal operation of a manufacturing and distribution supply chain. This includes the optimal placement of inventory (see item #15 in this article) within the supply chain, minimizing operating costs (including manufacturing costs, transportation costs, and distribution costs). This often involves the application of mathematical modelling techniques such as graph theory to find optimum delivery routes (and optimum locations of warehouses), the simplex algorithm, and Monte Carlo simulations. Read 21 data science systems used by Amazon to operate its business for typical applications. Again, despite being heavily statistical in nature, this is considered to be an operations research problem.
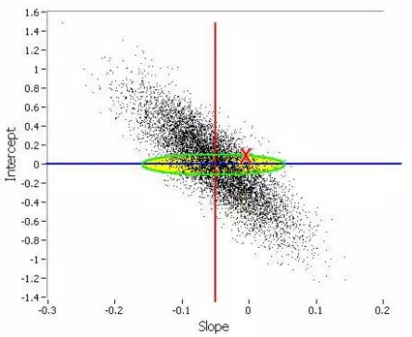
Source for picture: click here (regression via Monte Carlo simulations)
DSC Resources
- Career: Training | Books | Cheat Sheet | Apprenticeship | Certification | Salary Surveys | Jobs
- Knowledge: Research | Competitions | Webinars | Our Book | Members Only | Search DSC
- Buzz: Business News | Announcements | Events | RSS Feeds
- Misc: Top Links | Code Snippets | External Resources | Best Blogs | Subscribe | For Bloggers
Additional Reading
- The 10 Best Books to Read Now on IoT
- 50 Articles about Hadoop and Related Topics
- 10 Modern Statistical Concepts Discovered by Data Scientists
- Top data science keywords on DSC
- 4 easy steps to becoming a data scientist
- 13 New Trends in Big Data and Data Science
- 22 tips for better data science
- Data Science Compared to 16 Analytic Disciplines
- How to detect spurious correlations, and how to find the real ones
- 17 short tutorials all data scientists should read (and practice)
- 10 types of data scientists
- 66 job interview questions for data scientists
- High versus low-level data science
Follow us on Twitter: @DataScienceCtrl | @AnalyticBridge
){kind=link}