

Acing an interview in the field of machine learning could get difficult at times. The field is no doubt vast and ever-expanding and on top of it, the potential topics which could form a part of interview questions are not limited. The scope of sub-topics required as a skill set could vary for different recruiters/interviewers. But having said that there is some respite to this as we list down some of the most widely asks questions in the area. The Machine Learning interview questions list prepared is not exhaustive is totally based on the personal experience of many candidates who have appeared in such interviews and out of which many of them have also cleared it.
Have a Look into the top 20 Machine Learning Interview Questions & Answers
- What are the three different types of machine learning techniques?
Ans: Machine Learning is broadly divided into three different categories- supervised, unsupervised, and reinforcement learning.
Supervised learning is called so because the data set in which we apply supervised techniques needs to be labeled information or in other words supervised data. Labeled data often has two parts independent and dependent variables. Independent variables determine the nature of dependent variables.
An example of labeled observation could be the historical health information of a person (independent variables) which indicates whether the person is diabetic or not(dependent variable)
In the case of unsupervised learning, we only have the independent variables in our data set with the help of which we have to proceed with model building exercise.
Reinforcement learning, on the other hand, is an area of machine learning concerned with how an agent ought to take actions in an environment in order to maximize the notion of cumulative reward.

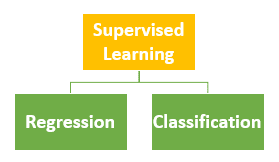
2. What are the different types of supervised learning?
Ans: This is a frequently asks Machine learning interview questions. Supervised learning is further divided into two types depending on the type of the target variable. We have regression-based methods for continuous and classification methods for discrete target variables. There are different types of regression and classification techniques.
3. Can you name some of the most commonly used supervised and unsupervised techniques?
Ans: This is a frequently asks Machine learning interview questions. Some of the most commonly used supervised techniques are
- Multiple linear regression
- Logistic regression
- Random forest
- Naive Bayes’
- K nearest neighbor
- Support Vector Machines
Some of the commonly used unsupervised techniques are
- Principal Component Analysis
- Clustering techniques
- Recommendation systems
- Association rules
4. How do we decide whether we need to apply a classification or a regression technique
Ans: Classification and regression are supervised learning techniques that frequently ask Machine learning interview questions. Hence the data set would also be labeled. Classification segregates or separates data points into predetermined categories. In the case of classification, the target variable would be discrete in nature like binary labels like yes or no, multi-level like the class I, class II and class III eg.
- predicting whether a person would buy a car or not
- predicting whether it would rain or not
- whether customers will open an email or not?
- will a customer payback credit card dues or default?
- Is the insurance claim fraud or genuine?
However, in the case of regression, the target variable would be continuous in nature like the age of a person, sales figures, domestic growth, GDP, population, etc eg.
- Prediction of the amount of rainfall
- Predicting the sales of new mobile connections
- Predicting revenue of a company
- Footfall in a mall
- Total retail spend by different customers
5. What is dimension reduction in Machine Learning?
Ans: Dimensionality reduction is a feature selection method that frequently asks Machine learning interview questions. It is used to reduce the number of variables under consideration in a data set. Dimensionality reduction can be performed by using PCA or TSNE. After applying dimensionality reduction, we are left with variables that are statistically more significant and hence more helpful for model building exercise.
6. What are the different ways to perform dimensionality reduction on a dataset?
Ans: This also frequently asks Machine learning interview questions. Some of the most commonly used dimensionality reduction techniques are
- Factor Analysis
- Principal Component Analysis
- Isomap
- Autoencoding
- Semidefinite Embedding
7. What is NLP and how it is related to machine learning?
Ans: This also frequently asks Machine learning interview questions. Natural Language Processing is a field which covers computer understanding and manipulation of human language. The field of study that focuses on the interactions between human language and computers is called Natural Language Processing.
NLP can be considered to be the intersection of computer science, artificial intelligence, and computational linguistics. NLP developers perform tasks such as automatic summarization, translation, named entity recognition, relationship extraction, sentiment analysis, speech recognition, and topic segmentation.
It is one fo the most fastly growing field in the area of AI and ML owing to the large amount of natural language that gets generated in the digital world of today.
8. How do you handle imbalanced data in machine learning?
Ans: Imbalanceness in data is a characteristic of supervised learning which is frequently asked in machine learning interview questions. Data is said to be imbalanced when the ratio of a level in the target variable is proportionately larger than the other. In the case of a binary target variable with ‘yes’ or ‘no’ levels, if the proportion of any one of them is significantly more than the other we call the data is imbalanced. Data could be imbalanced for categorical variables with more than two levels.
The above phenomenon in datasets often results in skewed model results if not handled properly. We can handle data imbalance by applying the below techniques
- Collect more data to even the imbalances in the dataset.
- Resample the dataset to correct for imbalances
- Apply upsampling and downsampling methods
9. What are the assumptions of the Ordinary Least Square(OLS) regression technique?
Ans: This also frequently asks Machine learning interview questions. The below assumption needs to hold good when we apply the OLS technique
- The sample data must represent the entire population
- The input and output variable must have a linear relationship
- The input variable must show homoscedasticity
- No multicollinearity among independent/ input variables
- Normal distribution of the output variable for any value of the input variable
- There should be any autocorrelation in the output/ dependent variable
10. How is machine learning different from deep learning?
Ans: This also frequently asks Machine learning interview questions. It is an application of artificial intelligence that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. Machine learning focuses on the development of computer programs that can access data and use it to learn for themselves.
Machines start learning with observations or data, such as examples, or instructions, in order to look for patterns in data and make better decisions in the future based on the examples that we provide. Computers learn automatically without human intervention or assistance and adjust actions accordingly.
Machine learning focuses on analyzing and learning from data based on features/variables fed into the model to make better decisions.
Deep Learning
Deep Learning is a subset of machine learning technique that constructs artificial neural networks to mimic the structure and function of the human brain. It focuses on feature extraction by deducing information from multiple layers, where each layer propagates the information to each layer for the final outcome.
In practice, deep learning, also known as deep structured learning or hierarchical learning, uses a large number hidden layers of nonlinear processing to extract features from data and transform the data into different levels of abstraction.
11. How would you handle missing data in a dataset?
Ans: Handling missing values is something that one would usually have to deal with when preparing the data for building models. The important questions here would be to understand the type of data that has missing values and accordingly decide the techniques to be use. Data types could either be discrete or continuous and hence the missing values as well. There are some machine learning models that could handle missing values, but most of them could not. Additionally, it is a good practice to handle missing values before model building. Some of the very basic techniques to handle missing values are mention below
- Continuous Variables: Replace missing with mean
- Ordinal Variables: Replace missing with the median
- Categorical Variables: Replace missing with the mode
- Dropping: When the proportion or the count of missing values is comparatively very less, we can also drop them
12. What are some of the most common steps for building an end to end ML solution?
Ans: This is also a frequently asked Machine learning interview question. Listed are some of the steps used during the development of an ML model
- Business Problem: Understand business objectives and convert it analytics problem
- Data Sources: Identify the required data sources, extract and aggregate the data
- Exploratory Analysis: Understand the data, examine the variables for errors, outliers, and missing values. Identify the relationship between different types of variables. Check for assumptions.
- Data Preparation: Exclusions, type conversions, outlier treatment, missing value treatment, derived variables, binning variables, dummy variables creation, etc.
- Feature Engineering: Avoid multicollinearity and optimize model complexity by reducing the number of input variables – variable cluster, correlation, factor analysis, etc.
- Data Split: Split the data into training and testing samples as per a suitable ratio
- Building Model: Fit, check accuracy, cross-validate, and tune the model with the help of parameters and hyperparameters.
- Model Testing: Check the model on the testing sample, run diagnostics, and iterate the model if required.
- Model Implementation: Prepare final model results- present the model and identify the limitations of the model
- Performance Tracking: Track model performance periodically and update it as and if require as and when data gets refreshed
13. What are some of the real life applications of ML algorithms?
Ans: This also frequently asks Machine learning interview questions. Some of the areas where machine learning is widely used are
- Bioinformatics
- Robotics Process Automation
- Natural Language Processing
- Sentiment Analysis
- Fraud detection
- Facial & Vocal recognition systems
- Anti-money laundering
14. What is the difference between data mining and machine learning?
Ans: This also frequently asks Machine learning interview questions. In data mining, we extract information to build insights from different types of sources and different types of data as well. Data mining is an exhaustive process and one can use statistical and visualization techniques to extract meaningful insights.
Whereas, machine learning is a field of study which deals with developing algorithm and methodologies on their own.
15. What was the last book or research paper that you read on machine learning?
Ans: This also frequently asks Machine learning interview questions. Candidates must always be well-read and aware of the latest developments being made in ML by reading published research papers and scientific journals. https://arxiv.org/ and https://www.kdnuggets.com/2017/04/top-20-papers-machine-learning.html is a good source to find various research papers in the field of machine and deep learning.
16. What is the significance of F1 score in machine learning algorithms
Ans: This also frequently asks Machine learning interview questions. F1 score is a performance measuring metric for supervised classification algorithms. It is the weighted average or the harmonic mean of the Recall and Precision values of a model. It’s is consider a robust technique to evaluate model performance.
Two additional terms comes into the picture with F1 score which is precision and recall

17. What is pruning in decision tree algorithms and how do you prune a decision tree?
Ans: This also frequently asks Machine learning interview questions. Pruning is a method that is applicable to tree-based methods hence it can be observed in supervised algorithms. Replacement of nodes of a decision tree in a top-down or bottom-up way is carried out during pruning. It becomes very helpful in increasing the accuracy of the decision tree while also reducing its complexity and overfitting.
The objective of prunning is to reduce the size of a tree without affecting the accuracy as measured by cross-validation. Below are the two most commonly used prunnnig methods
- Error based
- Cost complexity based
18. Why ensemble learning is used?
Ans: This also frequently asks Machine learning interview questions. Ensemble learning is use to improve the predictive performance of a model. Ensemble methods are usually consider to be better than the individual models.
19. When to use ensemble learning?
Ans: This also frequently asks Machine learning interview questions. Ensembling techniques are applies to improve the accuracy of machine learning techniques. During ensembling, a set of statistical methods are used which leads to improvement of model performance.
20. What are the two paradigms of ensemble methods?
Ans: This also frequently asks Machine learning interview questions. The two paradigms of ensemble methods are
- Sequential ensemble methods
- Parallel ensemble methods
Machine Learning Training online will make you an expert in Machine Learning.
{kind=link}