
Summary: If you’re still writing code to clean and prep your data you’re missing big opportunities for efficiency and consistency with modern data prep platforms.
 Two things are true.
Two things are true.
- Data prep still occupies about 80% of our model building time – the least enjoyable part.
- If you’re still writing code to do this from the ground up you’re overlooking big chances for efficiency and consistency.
Aside from de novo code, there are at least four categories of data prep platforms.
Fully Integrated: Many of the advanced analytic platforms have sophisticated data prep built in. Alteryx for example started off as a data prep platform and gradually added analytic tools to become a full service offering.
Stand Alone: There are still a wide variety of standalone data prep platforms. This is a marketing choice that seems to be based on a desire to service classic data analysts and citizen data scientists as well as the data science user with an emphasis on self-service. It also reaches users who have several analytic platforms but want to standardize data prep and can be an IT-driven choice to offload some ETL work to self-service. Trifacta and Datameer are examples of standalones.
Building Blocks: Some of the larger and more mature analytic providers like SAS and Oracle provide a variety of modules that can be used independently but are more frequently linked together into a fully integrated ensemble.
Automated Machine Learning (AML): By recent count there are now more than 20 providers claiming fully automated data-to-model machine learning. Tazi.ai is one example of a fully featured AML that automates even feature engineering and feature selection. Industries like insurance that produce and manage hundreds or even thousands of models have begun to embrace AML.
Data Prep Platforms Important Beyond Advanced Analytics
While data prep is central to the modeling activities of data scientists, many of these data prep tools seek to reach a broader self-service user.
Although our focus here is on advanced predictive analytics there is still a lot of value and activity in the broader analyst job. So whether the purpose is to build a sophisticated predictive model or simply to feed static historical data into data viz platforms for the purpose of eyeballing trends or any other data-driven initiative, all these uses critically value fast and flexible access to current data. Less and less that means going to IT for an ETL extract. Increasingly it means using a self-service tool like these.
How Do They Rank
I was motivated to write about data prep platforms now because of a particular opportunity. It happens that the reviews from three major research organizations are available at the same time. These are the Ovum Research 2018 Self Service Data Prep report, The Forrester Wave Q1 2017 Data Prep Tools report, and the Gartner Peer Insights Review for Data Prep Tools. All three can be accessed from the Trifacta home page.
Although there are some differences in who was included and the methodologies used for ranking, here are the three main charts.
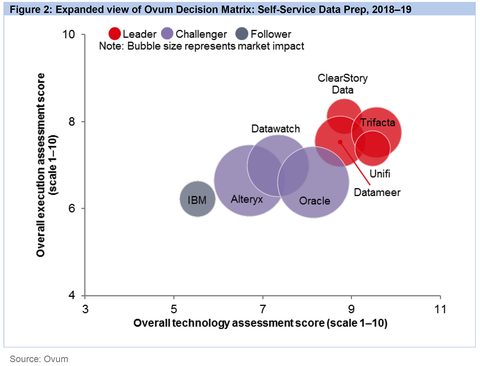
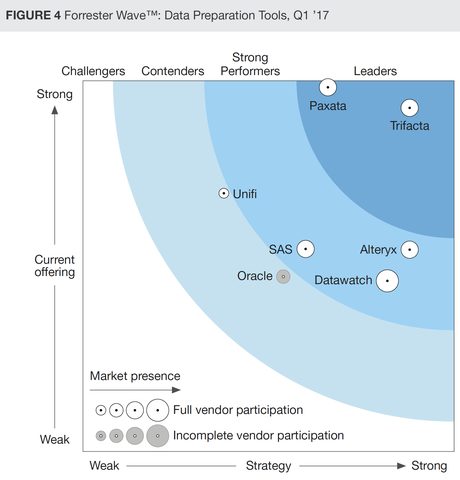
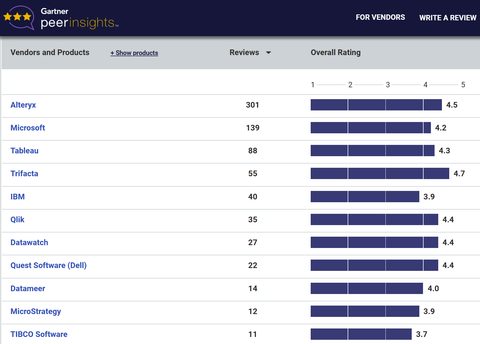
A note on the Gartner chart. Gartner peer rankings are based on surveys sent to users, not on independent Gartner evaluations. I’ve arbitrarily cut the chart off for any platforms that didn’t get at least 10 reviews. As all you data-smart readers will recognize, comparing numerical rankings of platforms with 300 rankings versus those with 11 or 12 is problematic at best.
What’s Included – What’s Different
What you would expect to find as core capabilities turns out to be pretty equal among the alternatives. That includes the ability to blend data sources, clean for missing or miscoded data, and do basic transforms.
It also includes the code-free ability to handle structured, semi-structured, and unstructured data.
Where this gets a little gray is in the border between data prep and modeling. The ability to perform transforms (e.g. normalize badly skewed distributions) or to create new features (e.g. the difference between dates or ratios between features) is sometimes excluded or manual, and sometimes augmented by ML suggestions to the user about the next steps they might take.
The real differentiators are a little more subtle.
Perils of Self Service and Other Differentiators
Without the single source of truth historically provided by EDWs in BI, the user is left a little to their own devices and can easily go astray. One differentiator is the inclusion of best in class data catalogues and data dictionaries.
A second issue is governance and permissions. How do you control access to sensitive information, whether PID or sensitive internal company information. An additional differentiator is the robustness of this governance, administration, and control feature.
Ovum identifies three ‘battleground’ characteristics among competitors. The first, above, is data governance.
The second is the ability of users to collaborate with one another in building the database. This varies fairly widely.
The third and perhaps most interesting is the manner in which the platform uses ML to suggest actions to the user. These might be sources for enrichment or more granular guidance about missing values, transforms, or other data features that the ML has determined would likely enhance the data for analysis.
From a purely data science perspective though, data prep platforms offer your data scientists working together a variety of benefits, primarily in speed to insight (as compared to code), standardization and repeatability (everyone hitting all the obvious steps for cleaning and transform), and finally to support multiple analytic techniques and platforms. As we all know some will still want to write their own code for the models themselves and some will have different preferences for platforms depending on the use case. These platforms, especially those that can be used standalone allow for complete flexibility for modeling once the less pleasant tasks of data prep are complete.
Other articles by Bill Vorhies.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at:
[email protected] or [email protected]
{kind=link}